gpu|苹果芯片吹上天,沉重代价在后面( 二 )
而在这样超额的晶体管背后,还有着恐怖的性能和外围电路。

文章插图
M1 Max 芯片X光照片
最显眼的,莫过于32核心苹果自研GPU核心阵列,整齐地排列在处理器的中心,由控制器和总线连接着,旁边是面积极大的片上SLC缓存,如果每一个缓存区域的大小是16M,整个处理器的SLC缓存可以达到64M。
尽管并不恰当,但这里可以拉来作个对比——目前主流安卓旗舰的处理器骁龙888,其L3缓存大小仅为4M!
左右两边则是4组128bit宽度的LPDDR5内存控制器,共同组成了M1 Max“毁天灭地”的内存最大带宽,在满配64G片上LPDDR5 6400内存的前提下,最大带宽达到了惊人的409.6GB/s。
而与之对比,桌面端intel的11代处理器11800H的最大内存带宽仅为51.2GB/s,这在一些内存带宽敏感的深度学习应用中将会提供无与伦比的硬件优势。
说完“超大杯”,继续看看“大杯”的M1 Pro。
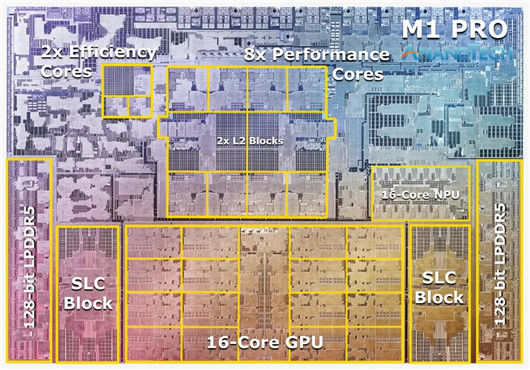
文章插图
M1Pro则是M1 Max这个“巨无霸”砍掉下半部分构成的。但是即便如此,其晶体管总数仍达到了惊人的337亿,并且还保留了32M的SLC缓存和2组128bit LPDDR5内存控制器。当然,“腰斩”后204.8GB/s的内存带宽依旧惊人。
挤完了“牙膏厂”,再来聊聊对于苏妈以及皮衣老黄的冲击。
如果不考虑各个架构和平台的差异以及各个API的效率差异,仅仅考虑GPU的浮点算力:
满血的M1 Pro为16核心GPU,浮点算力高达5.2Teraflops(tflops),足以对标AMD的RX5500显卡或者NVIDIA的RTX 1660 Ti;
哪怕是小刀的M1 Pro(14核心),算力也达到了4.6tflops,直接对标笔记本上满血的RX5500M、RTX1650 Super;
而大哥M1 Max的满血版更是恐怖如斯——浮点算力10.4TFlops,执行单元4096个,并发线程数极限98304个,纹理填充率每秒3270亿,像素填充率每秒1640亿。直接可以对标满血的RTX2080,或者降低了功耗的缩水版RTX3080。
皮衣老黄赢的如此艰难,至于苏妈,则需要祭出RX Vega56才能勉强将超越32核心GPU的满血M1 Max。
在这里,需要再一次强调一点——正如本文一开始解读的苹果发布会PPT里的内容,追上160w的RTX3080的浮点性能,M1 Max“满血版”只需要60w的功耗。
但是,库克,代价是什么呢?

文章插图
回顾M1芯片推出之时,那是在2020年的11月,差不多一年前。
【 gpu|苹果芯片吹上天,沉重代价在后面】彼时的M1,就拥有和现在M1 Pro/Max一样的单核心性能,而多核心性能的差距仅仅来自于核心数量从8变成了10。
GPU部分则更为简单,M1拥有最高8个GPU核心,对应M1 Pro和M1 Max的16核心/32核心,就是单纯的1:2:4的性能关系,无论是3D Mark分数还是浮点算力都是如此。
换而言之就是,在工艺没有进步的前提下,单核心一年时间没有任何变化。
如果往回看苹果A系列处理器的超大核心,每一代的进步都是极其可观的,但是从A12开始,这个进步开始放缓,到A13/M1这一代,苹果已经开始部分依赖代工工艺的进步和频率的提升了。
而苹果的对手,不知道是牙膏挤多了还是突然发力了,几乎不约而同将在明年推出极其具有竞争力的竞品。
首先是苹果的老伙伴对手。
如无意外,2022年将会是“牙膏厂”GPU爆发元年。最新的Xe架构GPU很快将会出现,在Intel当前制程工艺落后于台积电(自然也就落后于使用台积电先进工艺的苹果)的情况下,Intel仍预期将实现相对于苹果当前对比基准线产品“大约一倍”的能效提升。
不要认为这是吹牛,以目前泄漏的Intel DG2处理器满配置512处理单元来看,苹果在GPU上对Intel显卡集群的优势将会迅速缩小。
推荐阅读















- 海外市场|凭借近2亿的年销量,小米三年超越苹果的可能性有多大?
- 手机|苹果玩的是什么把戏,华为市场份额减少,反而iPhone13价格下调了
- Be苹果推出NBA限量版Beats耳机,庆祝NBA成立75周年
- iphone|苹果教你如何让 iPhone 电池保持健康
- 苹果|手机市场再次洗牌,华为跌至第六,苹果被荣耀超越,第一名很低调
- 荣耀|2021年第4季度手机销量出炉,荣耀首次位列第二,销量仅次于苹果
- 四季度|2021四季度苹果手机又赢了,荣VO米到底谁能第一个超越苹果?
- ios|苹果公司停止签署iOS 15.3 更新到15.3.1后无法降级
- ip5分钟卖出20万台!小米新品备受欢迎,这次苹果有压力了
- 魅族|库克被起诉?原因是苹果销量下滑,网友表示国产要崛起了