gpu|苹果芯片吹上天,沉重代价在后面( 三 )

文章插图
文章插图
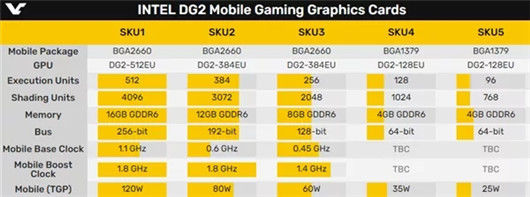
未来Intel DG2移动端独立显卡的预估配置与参数
至于AMD,其RNDA2架构也有着超过50%的预估提升。
目前苹果在桌面产品上的优势,若以非专业人士的视角来看,对于友商竞品而言堪称碾压性。但其代价就是:核心架构在这一年将原地踏步,以及将为超大规模台积电最新制程工艺而付出极高的成本。
须知在芯片设计领域,虽然同样的技术条件下规模越大(也就是晶体管数量越多)某些程度上产品的表现会变得更好。但是事实上就半导体产品的技术指标来说,同样的性能发挥和功耗下,用的晶体管越少,越说明你的能力强大,因为这意味着企业能用更低的成本做出来。
半导体作为一个研发密集的产业,其研发投入是固定投入,晶体管数量则是变动投入,随着产品的量产,大家自然希望固定投入占比越高越好,变动投入占比越低越好,实现同样的功能,自然是晶体管越少越好。
苹果的野望与国产的方向
很多人关心苹果新M1 Pro/Max系列处理器的CPU和GPU性能,但是很多人忽略了苹果在这几年一直着重发力的另一个领域,NPU,也就是神经处理单元。
NPU作为一种专用计算单元,对于神经网络,深度学习相关的运算相对于CPU/GPU这样的通用计算单元有着他们无法比拟的能效与性能优势,在图像识别,自然语言处理这类任务中NPU往往可以相对于CPU/GPU用更低的负载更高的速度更好的完成。
正因为优点如此显著,所以在移动端的许多未来应用中,端侧的NPU算力成为了许多公司的发展方向。无论是大陆的海思还是紫光,台湾的联发科,美国的高通,亦或者韩国的三星,他们的移动端处理器最近几年都在朝着强化神经网络算力的方向发展,这些算力最终都会落地。
文章插图
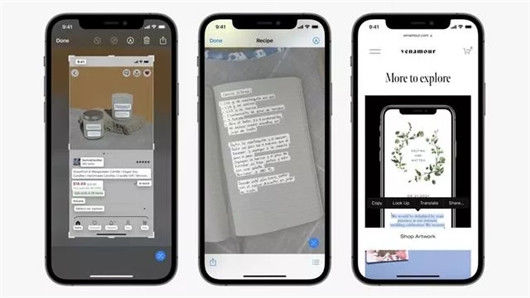
当然,在这一点上,苹果又走到了大家的前面。以苹果在iOS 15中更新的“文字识别”功能为例,苹果可以直接、实时,没有任何延迟地读取一张照片中的文字信息,并且允许用户简单的将其复制下来。
与之对比,类似的功能在安卓端,则通常需要例如小米传送门或者华为智慧识屏的特有功能——通过长按触发后经过运算分析后读取出来。这背后看似是功能的差异,实际上是算法和算力的巨大鸿沟,苹果无感,无延迟,无范围限制的文字识别,有非常大的概率是苹果为未来的可穿戴智能设备对外界环境低功耗全时段无延迟感知进行预先研发过程中的一个简单成果落地。
仅仅有感和无感、有延迟和无延迟之间,到底有何差距?

文章插图
万一呢?
我们不妨想象一下,未来的智能眼镜允许用户在转头一撇中,获取足够的信息,并且高效无感的为你处理完毕。因此,用户就不在需要反复看一个公告、反复记忆一个地标、反复的阅读一个内容,更不需要把他拍下来然后逐字逐句的读取。
未来的智能穿戴设备或许可以直接帮你进行阅读和理解,拆分和挑选重点,在国外旅游时的菜单翻译只需要一看就在瞬间完成替换,复杂公式的计算不再需要拍照录入而是自动实时的完成,这对生活的便利程度提升是难以想象的,而这一切的背后都需要强大的算力与算法的支撑。
然而,这或许只是苹果野心的一小部分。
国内目前在做较为先进制程芯片的公司有很多,大多数都是寻找台积电这类代工厂进行代工,少数会选择中芯国际这类国内的代工厂,同时也有大量的公司在做人工智能/神经网络相关的芯片研究与开发,例如寒武纪,地平线,芯原,中星微等等。
推荐阅读















- 海外市场|凭借近2亿的年销量,小米三年超越苹果的可能性有多大?
- 手机|苹果玩的是什么把戏,华为市场份额减少,反而iPhone13价格下调了
- Be苹果推出NBA限量版Beats耳机,庆祝NBA成立75周年
- iphone|苹果教你如何让 iPhone 电池保持健康
- 苹果|手机市场再次洗牌,华为跌至第六,苹果被荣耀超越,第一名很低调
- 荣耀|2021年第4季度手机销量出炉,荣耀首次位列第二,销量仅次于苹果
- 四季度|2021四季度苹果手机又赢了,荣VO米到底谁能第一个超越苹果?
- ios|苹果公司停止签署iOS 15.3 更新到15.3.1后无法降级
- ip5分钟卖出20万台!小米新品备受欢迎,这次苹果有压力了
- 魅族|库克被起诉?原因是苹果销量下滑,网友表示国产要崛起了