寒武纪官方详解云端 AI 芯片思元 370
IT之家 11 月 3 日消息,今天,寒武纪发布第三代云端 AI 芯片思元 370、基于思元 370 的两款加速卡 MLU370-S4 和 MLU370-X4。
同时,寒武纪全新升级了 Cambricon Neuware 软件栈,新增推理加速引擎 MagicMind,实现训推一体,显著提升了开发部署的效率,降低用户的学习成本、开发成本和运营成本。
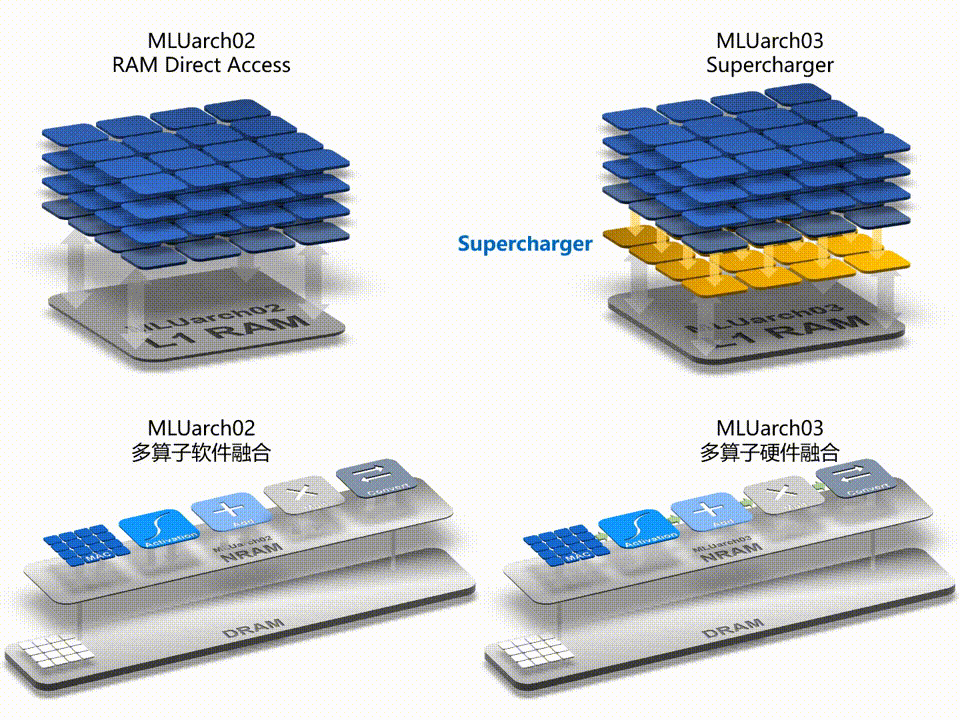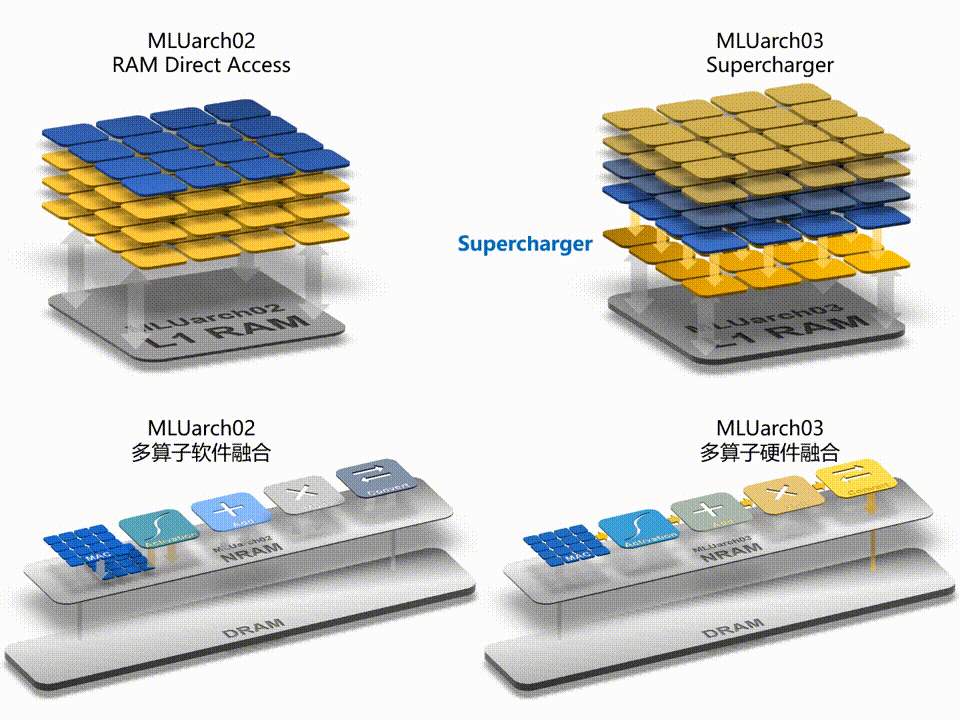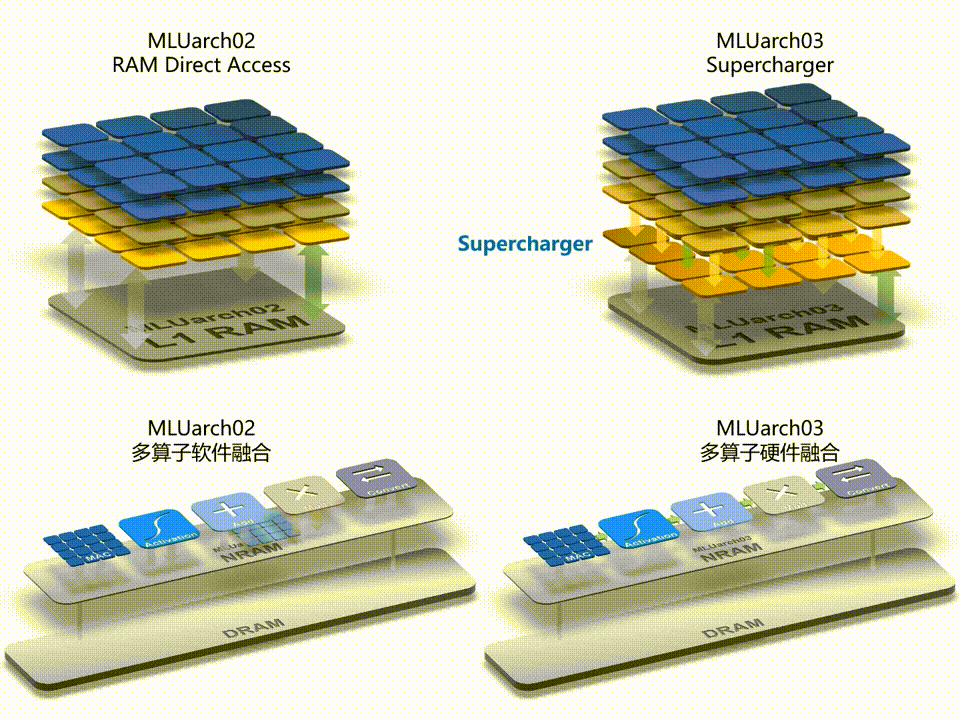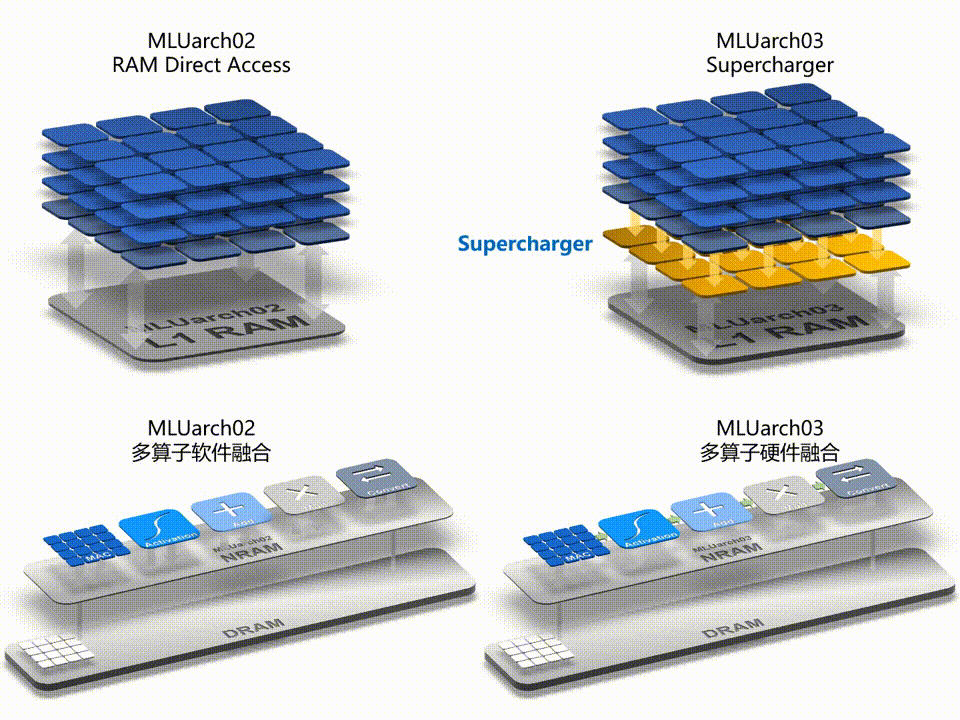
寒武纪发布了新一代智能处理器架构 MLUarch03,拥有新一代张量运算单元,内置 Supercharger 模块大幅提升各类卷积效率;采用全新的多算子硬件融合技术,在软件融合的基础上大幅减少算子执行时间;片上通讯带宽是上一代 MLUarch02 的 2 倍、片上共享缓存容量最高是 MLUarch02 的 2.75 倍;推出全新 MLUv03 指令集,更完备,更高效且向前兼容。
文章插图
▲ Supercharger 和多算子硬件融合技术
有 7nm 先进工艺和全新 MLUarch03 架构的加持,思元 370 芯片算力最高可达 256TOPS (INT8),是上一代产品思元 270 算力的 2 倍。相较于峰值算力的提升,思元 370 在实测性能和能效方面的表现更为优秀:以 ResNet-50 为例,MLU370-S4 加速卡(半高半长)实测性能为同尺寸主流 GPU 的 2 倍;MLU370-X4 加速卡(全高全长)实测性能与同尺寸主流 GPU 相当,能效则大幅领先。
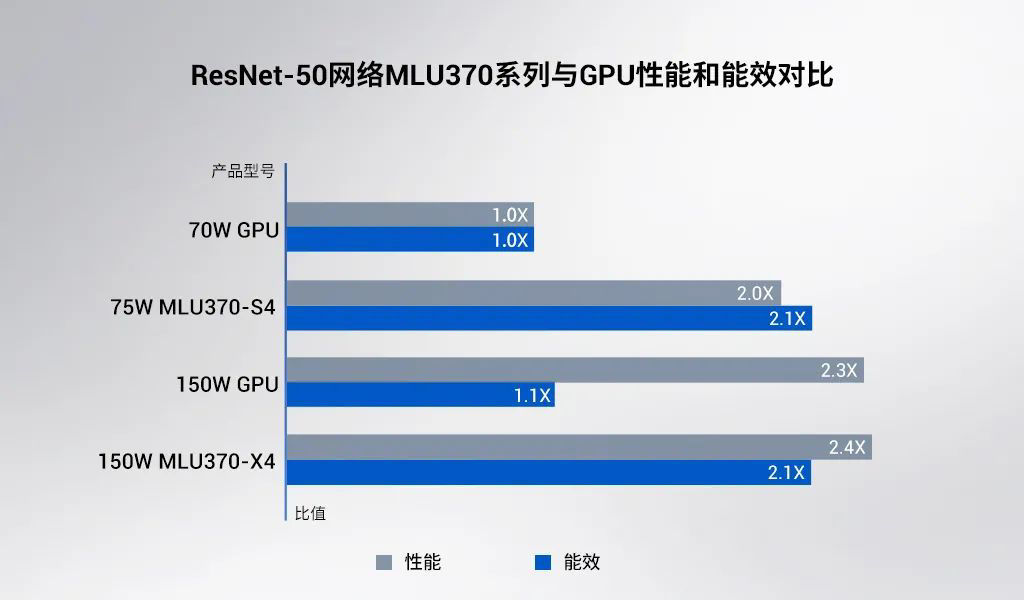
文章插图
▲ 7nm 先进工艺和全新 MLUarch03 架构加持,
思元 370 实测性能和实测能效超市场主流 GPU 产品
* 测试环境:
MLU370-S4:NF5468M6/2x Intel Xeon Gold 6330 CPU @ 2.0GHz/MagicMind v0.6
MLU370-X4:NF5468M6/2x Intel Xeon Gold 6330 CPU @ 2.0GHz/MagicMind v0.6
GPU 数据:ResNet-50 来自于相关产品官网,Transformer、VGG16、YOLOv3 均取自实测最大吞吐性能。
思元 370 全面加强了 FP16、BF16 以及 FP32 的浮点算力,同时支持推理和训练任务。此外,思元 370 还是国内第一颗支持 LPDDR5 的云端 AI 芯片,内存带宽是上一代产品的 3 倍,访存能效达 GDDR6 的 1.5 倍。
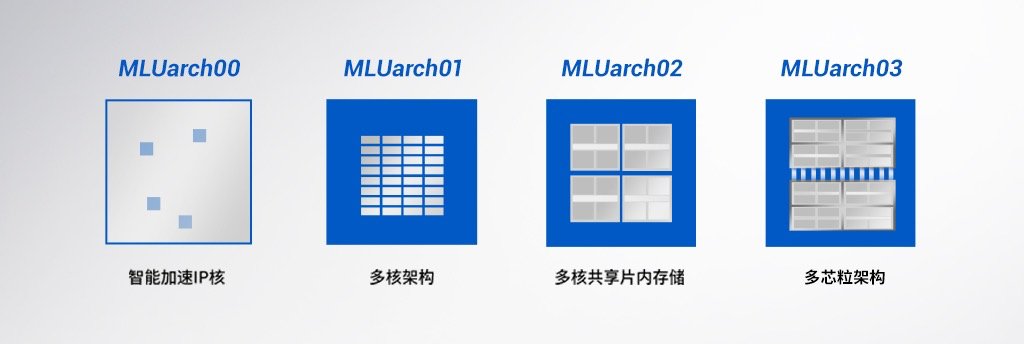
文章插图
▲ 寒武纪智能芯片架构演进
思元 370 采用 chiplet(芯粒)技术,在一颗芯片中封装 2 颗 AI 计算芯粒(MLU-Die),每一个 MLU-Die 具备独立的 AI 计算单元、内存、IO 以及 MLU-Fabric 控制和接口,通过 MLU-Fabric 保证两个 MLU-Die 间的高速通讯,可以通过不同 MLU-Die 组合规格多样化的产品,为用户提供适用不同场景的高性价比 AI 芯片。

文章插图
▲ 思元 370 采用 chiplet 技术,可实现不同算力、内存和编解码器的组合
MLU-Fabric 是实现芯粒技术的关键所在。它为两个 MLU-Die 提供低功耗、低延时和超高带宽的互联,支持芯片上实现统一的内存获取和地址映射,创建虚拟通路避免进程死锁,支持数据校验错误发生时进行数据重传,保证数据准确性。
【 寒武纪官方详解云端 AI 芯片思元 370】得益于芯粒技术,思元 370 可通过不同的组合为客户提供更多样化的产品选择,此次寒武纪发布了两款加速卡,未来还将推出更多基于思元 370 的产品。
MagicMind 是寒武纪全新打造的推理加速引擎,也是业界首个基于 MLIR 图编译技术达到商业化部署能力的推理引擎。MagicMind 支持跨框架的模型解析、自动后端代码生成及优化。在 MLU、GPU、CPU 训练好的算法模型上,借助 MagicMind,用户仅需投入极少的开发成本,即可将推理业务部署到寒武纪全系列产品上,并获得颇具竞争力的性能。
MagicMind 的优势不仅在于可以提供极致的性能、可靠的精度以及简洁的编程接口,让用户能够专注于业务本身,无需理解芯片更多底层细节就可实现模型的快速高效部署,MagicMind 插件化的设计还可以满足在性能或功能上追求差异化竞争力的客户需求。
推荐阅读













- 政策|浙江省“抢人”:创业失败贷款不用还?官方回应来了
- 天玑|OPPO首款平板外观官方曝光;vivo高管暗示天玑9000旗舰很快登场
- s12|获得KPL官方认证的轻薄影像旗舰?vivo这一步跨得有点大
- 性能|AMD R7 6800U 核显官方测试:性能超英伟达 MX450
- 8g+256g|男子花7900元买了台二手手机,价格还比官方新机贵,店家:现在都是加价拿货
- supervooc|OnePlus Nord CE 2 官方渲染 4K 分辨率泄露
- 新闻稿|美通社再度成为世界移动通信大会(MWC)的官方合作伙伴
- 官方|华为开卖官方二手机,售价2999元起,消费者能否买账?
- 荣耀|官方:荣耀Magic4系列将于MWC大会发布
- iFixit|iFixit拆解Steam Deck,并将正式出售来自Valve官方的替换零件