追风赶月莫停留,平芜尽处是春山。这篇文章主要讲述Android中三种常用解析XML的方式(DOMSAXPULL)简介及区别相关的知识,希望能为你提供帮助。
XML在各种开发中都广泛应用,android也不例外。作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能。今天就由我向大家介绍一下在Android平台下几种常见的XML解析和创建的方法。在Android中,常见的XML解析器分别为SAX解析器、DOM解析器和PULL解析器,下面,我将一一向大家详细介绍。
SAX解析器:
SAX(Simple API for XML)解析器是一种基于事件的解析器,它的核心是事件处理模式,主要是围绕着事件源以及事件处理器来工作的。当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
【Android中三种常用解析XML的方式(DOMSAXPULL)简介及区别】SAX解析器的优点是解析速度快,占用内存少。非常适合在Android移动设备中使用。
DOM解析器:
DOM是基于树形结构的的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树、检索所需数据。分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息。
由于DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。
PULL解析器:
PULL解析器的运行方式和SAX类似,都是基于事件的模式。不同的是,在PULL解析过程中,我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法,执行我们的代码。PULL解析器小巧轻便,解析速度快,简单易用,非常适合在Android移动设备中使用,Android系统内部在解析各种XML时也是用PULL解析器。
三种解析方式区别:
(1)SAX解析器的优点是解析速度快,占用内存少。
DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。
PULL解析器的运行方式和SAX类似,都是基于事件的模式。PULL解析器小巧轻便,解析速度快,简单易用。
(2)DOM,它是生成一个树,有了树以后你搜索、查找都可以做。
SAX和PULL是基于流的,就是解析器从头到尾解析一遍xml文件,解析完了以后你不过想再查找重新解析。
SAX和PULL的区别:
(1)sax的原理是解析器解析过程中通过回调把tag/value值等传给你,你可以比较、操作。
而pull的原理是它只告诉你一个tag开始或者结束了,至于tag/value的值是什么需要你自己去向parser问,所以叫做pull,而sax看起来
是push给你的。
(2)如果在一个XML文档中我们只需要前面一部分数据,但是使用SAX方式或DOM方式会对整个文档进行解析,尽管XML文档中后面的大部分数据我们其实都不需要解析,因此这样实际上就浪费了处理资源。使用PULL方式正合适。
Pull解析器和SAX解析器虽有区别但也有相似性。他们的区别为:SAX解析器的工作方式是自动将事件推入注册的事件处理器进行处理,因此你不能控制事件的处理主动结束;而Pull解析器的工作方式为允许你的应用程序代码主动从解析器中获取事件,正因为是主动获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析。也就是说pull是一个while循环,随时可以跳出,而sax不是,sax是只要解析了,就必须解析完成,在解析过程中在读取到特定tag时调用相应处理事件。这是他们主要的区别。
而他们的相似性在运行方式上,Pull解析器也提供了类似SAX的事件,开始文档START_DOCUMENT和结束文档END_DOCUMENT,开始元素START_TAG和结束元素END_TAG,遇到元素内容TEXT等,但需要调用next() 方法提取它们(主动提取事件)。
以上三种解析器,都是非常实用的解析器,我将会一一介绍。我们将会使用这三种解析技术完成一项共同的任务。
我们新建一个项目,项目结构如下:
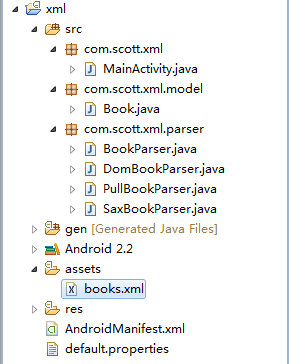
文章图片
我会在项目的assets目录中放置一个XML文档books.xml,内容如下:
< ?xml version="1.0" encoding="utf-8"?> < books> < book> < id> 1001< /id> < name> Thinking In java< /name> < price> 80.00< /price> < /book> < book> < id> 1002< /id> < name> Core Java< /name> < price> 90.00< /price> < /book> < book> < id> 1003< /id> < name> Hello, Andriod< /name> < price> 100.00< /price> < /book> < /books>
然后我们分别使用以上三种解析技术解析文档,得到一个List< Book> 的对象,先来看一下Book.java的代码:
package com.scott.xml.model; public class Book { private int id; private String name; private float price; public int getId() { return id; }public void setId(int id) { this.id = id; }public String getName() { return name; }public void setName(String name) { this.name = name; }public float getPrice() { return price; }public void setPrice(float price) { this.price = price; }@Override public String toString() { return "id:" + id + ", name:" + name + ", price:" + price; } }
最后,我们还要把这个集合对象中的数据生成一个新的XML文档,如图:

文章图片
生成的XML结构跟原始文档略有不同,是下面这种格式:
< ?xml version="1.0" encoding="UTF-8"?> < books> < book id="1001"> < name> Thinking In Java< /name> < price> 80.0< /price> < /book> < book id="1002"> < name> Core Java< /name> < price> 90.0< /price> < /book> < book id="1003"> < name> Hello, Andriod< /name> < price> 100.0< /price> < /book> < /books>
接下来,就该介绍操作过程了,我们先为解析器定义一个BookParser接口,每种类型的解析器需要实现此接口。
BookParser.java代码如下:
package com.scott.xml.parser; import java.io.InputStream; import java.util.List; import com.scott.xml.model.Book; public interface BookParser { /** * 解析输入流 得到Book对象集合 * @param is * @return * @throws Exception */ public List< Book> parse(InputStream is) throws Exception; /** * 序列化Book对象集合 得到XML形式的字符串 * @param books * @return * @throws Exception */ public String serialize(List< Book> books) throws Exception; }
好了,我们就该一个一个的实现该接口,完成我们的解析过程。
使用SAX解析器:
SaxBookParser.java代码如下:
package com.scott.xml.parser; import java.io.InputStream; import java.io.StringWriter; import java.util.ArrayList; import java.util.List; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import javax.xml.transform.OutputKeys; import javax.xml.transform.Result; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.sax.SAXTransformerFactory; import javax.xml.transform.sax.TransformerHandler; import javax.xml.transform.stream.StreamResult; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.AttributesImpl; import org.xml.sax.helpers.DefaultHandler; import com.scott.xml.model.Book; public class SaxBookParser implements BookParser {@Override public List< Book> parse(InputStream is) throws Exception { SAXParserFactory factory = SAXParserFactory.newInstance(); //取得SAXParserFactory实例 SAXParser parser = factory.newSAXParser(); //从factory获取SAXParser实例 MyHandler handler = new MyHandler(); //实例化自定义Handler parser.parse(is, handler); //根据自定义Handler规则解析输入流 return handler.getBooks(); }@Override public String serialize(List< Book> books) throws Exception { SAXTransformerFactory factory = (SAXTransformerFactory) TransformerFactory.newInstance(); //取得SAXTransformerFactory实例 TransformerHandler handler = factory.newTransformerHandler(); //从factory获取TransformerHandler实例 Transformer transformer = handler.getTransformer(); //从handler获取Transformer实例 transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); // 设置输出采用的编码方式 transformer.setOutputProperty(OutputKeys.INDENT, "yes"); // 是否自动添加额外的空白 transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "no"); // 是否忽略XML声明StringWriter writer = new StringWriter(); Result result = new StreamResult(writer); handler.setResult(result); String uri = ""; //代表命名空间的URI 当URI无值时 须置为空字符串 String localName = ""; //命名空间的本地名称(不包含前缀) 当没有进行命名空间处理时 须置为空字符串handler.startDocument(); handler.startElement(uri, localName, "books", null); AttributesImpl attrs = new AttributesImpl(); //负责存放元素的属性信息 char[] ch = null; for (Book book : books) { attrs.clear(); //清空属性列表 attrs.addAttribute(uri, localName, "id", "string", String.valueOf(book.getId())); //添加一个名为id的属性(type影响不大,这里设为string) handler.startElement(uri, localName, "book", attrs); //开始一个book元素 关联上面设定的id属性handler.startElement(uri, localName, "name", null); //开始一个name元素 没有属性 ch = String.valueOf(book.getName()).toCharArray(); handler.characters(ch, 0, ch.length); //设置name元素的文本节点 handler.endElement(uri, localName, "name"); handler.startElement(uri, localName, "price", null); //开始一个price元素 没有属性 ch = String.valueOf(book.getPrice()).toCharArray(); handler.characters(ch, 0, ch.length); //设置price元素的文本节点 handler.endElement(uri, localName, "price"); handler.endElement(uri, localName, "book"); } handler.endElement(uri, localName, "books"); handler.endDocument(); return writer.toString(); }//需要重写DefaultHandler的方法 private class MyHandler extends DefaultHandler {private List< Book> books; private Book book; private StringBuilder builder; //返回解析后得到的Book对象集合 public List< Book> getBooks() { return books; }@Override public void startDocument() throws SAXException { super.startDocument(); books = new ArrayList< Book> (); builder = new StringBuilder(); }@Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { super.startElement(uri, localName, qName, attributes); if (localName.equals("book")) { book = new Book(); } builder.setLength(0); //将字符长度设置为0 以便重新开始读取元素内的字符节点 }@Override public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); builder.append(ch, start, length); //将读取的字符数组追加到builder中 }@Override public void endElement(String uri, String localName, String qName) throws SAXException { super.endElement(uri, localName, qName); if (localName.equals("id")) { book.setId(Integer.parseInt(builder.toString())); } else if (localName.equals("name")) { book.setName(builder.toString()); } else if (localName.equals("price")) { book.setPrice(Float.parseFloat(builder.toString())); } else if (localName.equals("book")) { books.add(book); } } } }
代码中,我们定义了自己的事件处理逻辑,重写了DefaultHandler的几个重要的事件方法。下面我为大家着重介绍一下DefaultHandler的相关知识。DefaultHandler是一个事件处理器,可以接收解析器报告的所有事件,处理所发现的数据。它实现了EntityResolver接口、DTDHandler接口、ErrorHandler接口和ContentHandler接口。这几个接口代表不同类型的事件处理器。我们着重介绍一下ContentHandler接口。结构如图:
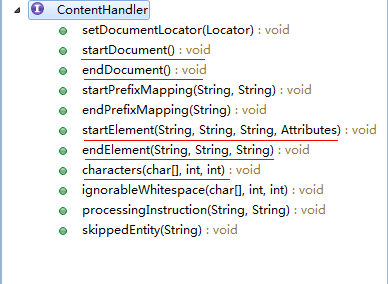
文章图片
这几个比较重要的方法已被我用红线标注,DefaultHandler实现了这些方法,但在方法体内没有做任何事情,因此我们在使用时必须覆写相关的方法。最重要的是startElement方法、characters方法和endElement方法。当执行文档时遇到起始节点,startElement方法将会被调用,我们可以获取起始节点相关信息;然后characters方法被调用,我们可以获取节点内的文本信息;最后endElement方法被调用,我们可以做收尾的相关操作。
最后,我们需要调用SAX解析程序,这个步骤在MainActivity中完成:
package com.scott.xml; import java.io.FileOutputStream; import java.io.InputStream; import java.util.List; import android.app.Activity; import android.content.Context; import android.os.Bundle; import android.util.Log; import android.view.View; import android.widget.Button; import com.scott.xml.model.Book; import com.scott.xml.parser.BookParser; import com.scott.xml.parser.SaxBookParser; public class MainActivity extends Activity {private static final String TAG = "XML"; private BookParser parser; private List< Book> books; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); Button readBtn = (Button) findViewById(R.id.readBtn); Button writeBtn = (Button) findViewById(R.id.writeBtn); readBtn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { try { InputStream is = getAssets().open("books.xml"); parser = new SaxBookParser(); //创建SaxBookParser实例 books = parser.parse(is); //解析输入流 for (Book book : books) { Log.i(TAG, book.toString()); } } catch (Exception e) { Log.e(TAG, e.getMessage()); } } }); writeBtn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { try { String xml = parser.serialize(books); //序列化 FileOutputStream fos = openFileOutput("books.xml", Context.MODE_PRIVATE); fos.write(xml.getBytes("UTF-8")); } catch (Exception e) { Log.e(TAG, e.getMessage()); } } }); } }
界面就两个按钮,顺便给大家贴上:
文章图片
点击“readXML”按钮,将会调用SAX解析器解析文档,并在日志台打印相关信息:

文章图片
然后再点击“writeXML”按钮,将会在该应用包下的files目录生成一个books.xml文件:
文章图片
使用DOM解析器:
DomBookParser.java代码如下:
package com.scott.xml.parser; import java.io.InputStream; import java.io.StringWriter; import java.util.ArrayList; import java.util.List; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.OutputKeys; import javax.xml.transform.Result; import javax.xml.transform.Source; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import com.scott.xml.model.Book; public class DomBookParser implements BookParser {@Override public List< Book> parse(InputStream is) throws Exception { List< Book> books = new ArrayList< Book> (); DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //取得DocumentBuilderFactory实例 DocumentBuilder builder = factory.newDocumentBuilder(); //从factory获取DocumentBuilder实例 Document doc = builder.parse(is); //解析输入流 得到Document实例 Element rootElement = doc.getDocumentElement(); NodeList items = rootElement.getElementsByTagName("book"); for (int i = 0; i < items.getLength(); i++) { Book book = new Book(); Node item = items.item(i); NodeList properties = item.getChildNodes(); for (int j = 0; j < properties.getLength(); j++) { Node property = properties.item(j); String nodeName = property.getNodeName(); if (nodeName.equals("id")) { book.setId(Integer.parseInt(property.getFirstChild().getNodeValue())); } else if (nodeName.equals("name")) { book.setName(property.getFirstChild().getNodeValue()); } else if (nodeName.equals("price")) { book.setPrice(Float.parseFloat(property.getFirstChild().getNodeValue())); } } books.add(book); } return books; }@Override public String serialize(List< Book> books) throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.newDocument(); //由builder创建新文档Element rootElement = doc.createElement("books"); for (Book book : books) { Element bookElement = doc.createElement("book"); bookElement.setAttribute("id", book.getId() + ""); Element nameElement = doc.createElement("name"); nameElement.setTextContent(book.getName()); bookElement.appendChild(nameElement); Element priceElement = doc.createElement("price"); priceElement.setTextContent(book.getPrice() + ""); bookElement.appendChild(priceElement); rootElement.appendChild(bookElement); }doc.appendChild(rootElement); TransformerFactory transFactory = TransformerFactory.newInstance(); //取得TransformerFactory实例 Transformer transformer = transFactory.newTransformer(); //从transFactory获取Transformer实例 transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); // 设置输出采用的编码方式 transformer.setOutputProperty(OutputKeys.INDENT, "yes"); // 是否自动添加额外的空白 transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "no"); // 是否忽略XML声明StringWriter writer = new StringWriter(); Source source = new DOMSource(doc); //表明文档来源是doc Result result = new StreamResult(writer); //表明目标结果为writer transformer.transform(source, result); //开始转换return writer.toString(); }}
然后再MainActivity中只需改一个地方:
readBtn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { try { InputStream is = getAssets().open("books.xml"); //parser = new SaxBookParser(); parser = new DomBookParser(); books = parser.parse(is); for (Book book : books) { Log.i(TAG, book.toString()); } } catch (Exception e) { Log.e(TAG, e.getMessage()); } } );
执行结果是一样的。
使用PULL解析器:
PullBookParser.java代码如下:
package com.scott.xml.parser; import java.io.InputStream; import java.io.StringWriter; import java.util.ArrayList; import java.util.List; import org.xmlpull.v1.XmlPullParser; import org.xmlpull.v1.XmlSerializer; import android.util.Xml; import com.scott.xml.model.Book; public class PullBookParser implements BookParser {@Override public List< Book> parse(InputStream is) throws Exception { List< Book> books = null; Book book = null; //XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); //XmlPullParser parser = factory.newPullParser(); XmlPullParser parser = Xml.newPullParser(); //由android.util.Xml创建一个XmlPullParser实例 parser.setInput(is, "UTF-8"); //设置输入流 并指明编码方式int eventType = parser.getEventType(); while (eventType != XmlPullParser.END_DOCUMENT) { switch (eventType) { // 判断当前事件是否为文档开始事件 case XmlPullParser.START_DOCUMENT: books = new ArrayList< Book> (); break; // 判断当前事件是否为标签元素开始事件 case XmlPullParser.START_TAG: if (parser.getName().equals("book")) { book = new Book(); } else if (parser.getName().equals("id")) { eventType = parser.next(); //让解析器指向id属性的值 book.setId(Integer.parseInt(parser.getText())); } else if (parser.getName().equals("name")) { eventType = parser.next(); //让解析器指向name属性的值 book.setName(parser.getText()); } else if (parser.getName().equals("price")) { eventType = parser.next(); book.setPrice(Float.parseFloat(parser.getText())); } break; case XmlPullParser.END_TAG: if (parser.getName().equals("book")) { books.add(book); book = null; } break; } // 进入下一个元素并触发相应事件 eventType = parser.next(); } return books; }@Override public String serialize(List< Book> books) throws Exception { //XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); //XmlSerializer serializer = factory.newSerializer(); XmlSerializer serializer = Xml.newSerializer(); //由android.util.Xml创建一个XmlSerializer实例 StringWriter writer = new StringWriter(); serializer.setOutput(writer); //设置输出方向为writer serializer.startDocument("UTF-8", true); serializer.startTag("", "books"); for (Book book : books) { serializer.startTag("", "book"); serializer.attribute("", "id", book.getId() + ""); serializer.startTag("", "name"); serializer.text(book.getName()); serializer.endTag("", "name"); serializer.startTag("", "price"); serializer.text(book.getPrice() + ""); serializer.endTag("", "price"); serializer.endTag("", "book"); } serializer.endTag("", "books"); serializer.endDocument(); return writer.toString(); } }
然后再对MainActivity做以下更改:
readBtn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { try { InputStream is = getAssets().open("books.xml"); //parser = new SaxBookParser(); //parser = new DomBookParser(); parser = new PullBookParser(); books = parser.parse(is); for (Book book : books) { Log.i(TAG, book.toString()); } } catch (Exception e) { Log.e(TAG, e.getMessage()); } } });
public class ReadXmlPullParse {private List< Server> serverList=null; private Server server=null; public List< Server> parseServer(Context context, int source) throws Exception{//pull解析器方式 XmlPullParser xml=Xml.newPullParser(); //由android.util.Xml创建一个XmlPullParser实例 xml=context.getResources().getXml(source); //is=getActivity().getAssets().open(EBConstant.XML_LOCALBOOKSINFO_FILENAME); //xml.setInput(is, GamConstants.ENCODINGFORMAT); //设置输入流 并指明编码方式 int eventType=xml.getEventType(); while(eventType != XmlPullParser.END_DOCUMENT){ switch (eventType) { // 判断当前事件是否为文档开始事件 case XmlPullParser.START_DOCUMENT:{ serverList=new ArrayList< Server> (); break; } // 判断当前事件是否为标签元素开始事件 case XmlPullParser.START_TAG:{ if(xml.getName().equals(GamConstants.XML_SDKCONFIG_SERVER)){ server=new Server(); }else if(xml.getName().equals(GamConstants.XML_SDKCONFIG_SERVER_SERVERID)){ eventType=xml.next(); //让解析器指向属性的值 server.setServerId(Integer.parseInt(xml.getText())); }else if(xml.getName().equals(GamConstants.XML_SDKCONFIG_SERVER_URL)){ eventType=xml.next(); //让解析器指向属性的值 server.setUrl(xml.getText()); }else if(xml.getName().equals(GamConstants.XML_SDKCONFIG_SERVER_MAXSENDCOUNT)){ eventType=xml.next(); //让解析器指向属性的值 server.setMaxSendCount(Integer.parseInt(xml.getText())); } break; } case XmlPullParser.END_TAG:{ if(xml.getName().equals(GamConstants.XML_SDKCONFIG_SERVER)){ serverList.add(server); server=null; } break; } } // 进入下一个元素并触发相应事件 eventType = xml.next(); }return serverList; } }
和其他两个执行结果都一样。
对于这三种解析器各有优点,我个人比较倾向于PULL解析器,因为SAX解析器操作起来太笨重,DOM不适合文档较大,内存较小的场景,唯有PULL轻巧灵活,速度快,占用内存小,使用非常顺手。
推荐阅读














- 聊一聊 Android 6.0 的运行时权限
- 聊聊Web AppHybrid App与Native App的设计差异
- Spring中ClassPathXmlApplication与FileSystemXmlApplicationContext的区别以及ClassPathXmlApplicationContext 的具
- 电商App软件开发系统功能
- Linux/Android多点触摸协议
- Eclipse和JavaFX集成详细步骤
- JavaFX VBox
- Android Studio 打印调试信息
- Building and using plug-ins for Android