无损放大图片和视频?这两款AI工具值得拥有
身为一个编辑,除了文字工作这个主要的工作内容之外,经常还需要考虑一个很重要的问题:插图。
全是文字的文章肯定没有图文形式的文章抓人眼球,更别提这个视频当道的年代了,因此每次撰写文章的时候,笔者都要在无版权图片网站精挑细选,让图片和文章主旨契合,并且最好是高分辨率的图像。
但意外也总是有的,有的时候遇到了分辨率不足但偏偏最适合的图像,就很让人苦恼了,直接将低分辨率图像插入文章中,会很明显地感觉到视觉上的不舒适,虽然现在PS甚至是Windows自带的画图工具都能修改图片分辨率,但强行拉伸的结果只会是:图片非常糊。
可以看到,在进行图片拉伸后,图片边缘已经出现了明显的毛刺感。
文章插图
那有没有什么方法能够让图片无损放大呢?
别说,还真有,这个来自GitHub的项目“waifu2x”就能做到。
项目地址为https://github.com/nagadomi/waifu2x,有兴趣的朋友可以研究一下,网页版地址为http://waifu2x.udp.jp/。
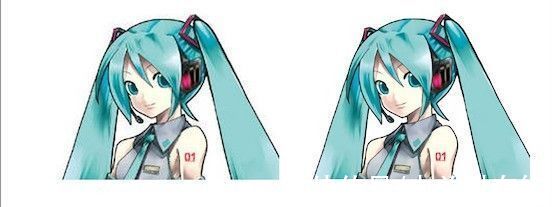
闲话少说,这里直接放使用waifu2x和普通拉伸图片后的对比(左侧为拉伸,右侧为使用waifu2x的效果)。
文章插图
可以看到,使用waifu2x放大图片后,“5G”边缘的毛刺感不再明显,虽然部分区域还存在噪点问题,但整体上来说,比直接拉伸的效果要好太多。
那为什么waifu2x可以做到无损放大图片呢?这是因为waifu2x使用了名为SRCNN的卷积算法,传统意义上来说,图像超分辨率问题研究的是在输入一张低分辨率图像时(LR),如何得到一张高分辨率图像(HR)。传统的图像插值算法可以在某种程度上获得这种效果,比如最近邻插值、双线性插值和双三次插值等,但是这些算法获得的高分辨率图像效果并不理想。
SRCNN是首个使用CNN结构(即基于深度学习)的端到端的超分辨率算法,它将整个算法流程用深度学习的方法实现了,并且效果比传统多模块集成的方法好。SRCNN流程如下:首先输入预处理。对输入的低分辨率LR图像使用bicubic算法进行放大,放大为目标尺寸。那么接下来算法的目标就是将输入的比较模糊的LR图像,经过卷积网络的处理,得到超分辨率SR的图像,使它尽可能与原图的高分辨率HR图像相似。
【 无损放大图片和视频?这两款AI工具值得拥有】与Bicubic、SC、NE+LLE、KK、ANR、A+这些超分算法相比,SRCNN在大部分指标上都表现最好,且复原速度也在前列,且RGB通道联合训练效果最好,这就意味着相比照片,waifu2x在放大插画(你们最喜欢的二次元图片)时会更有优势。
关于SRCNN卷积算法,可以到https://arxiv.org/abs/1501.00092了解更多详情。
那既然图片可以无损放大,视频呢?
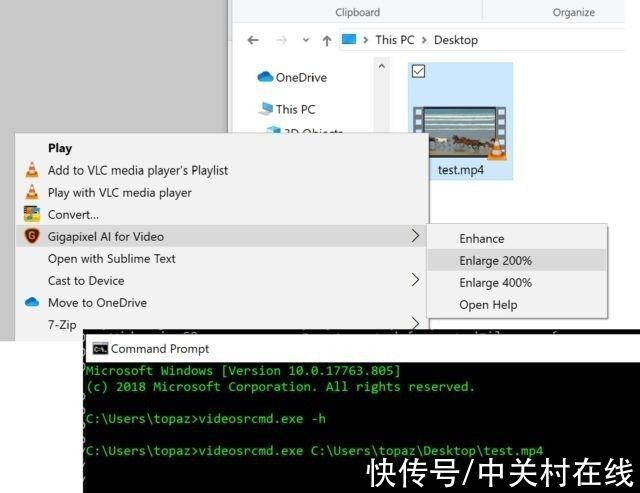
结果当然也是可行的,不过这次用到的工具,叫做Topaz Gigapixel AI for Video,这个软件通过数千个视频进行培训,并结合来自多个输入视频帧的信息,通过真实的细节和运动一致性将视频放大至8K分辨率。
文章插图
作为一个AI软件,它需要一台快速的计算机。推荐的系统配置是32 GB RAM加上具有6GB或更大显存的NVIDIA显卡。虽然也勉强能在旧电脑上跑,但速度会非常慢。
那Topaz Gigapixel AI for Video是如何做到放大视频的呢?其实在安装的时候,会发现这个软件会安装TensorFlow库和cuDNN库,所以很明显,该软件就是运用基于深度学习的卷积神经网络对每一帧进行处理,全程跑CUDA单元(要不然也不会这么慢了)。
推荐阅读













- 投稿|中国企业的冬奥进行时
- 投稿|天猫能否再造一个京东?
- 投稿|主播围攻星巴克
- 投稿|一场世纪收购案后的30天
- 投稿|薇娅停播,助播上位
- 投稿|滑雪的尽头是骨科?
- 投稿|喜茶、奈雪,挤不进县城
- 投稿|星巴克打败了星巴克
- 投稿|亿万滑雪产业,真的出圈了?
- 投稿|书亦烧仙草,值不值100亿?