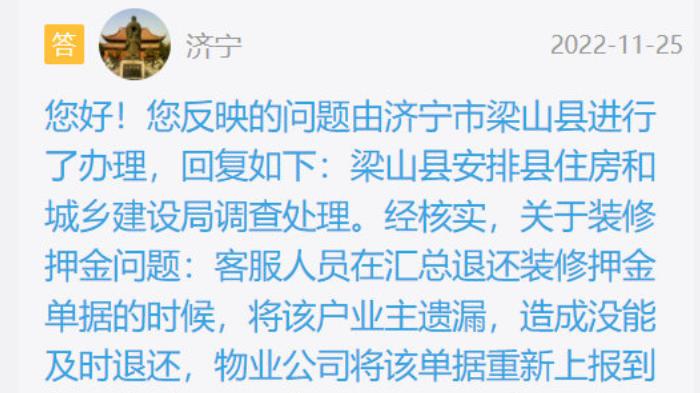
GoиҜӯиЁҖвҖ”вҖ”sync.MapиҜҰи§Ј sync.MapжҳҜ1.9жүҚжҺЁиҚҗзҡ„并еҸ‘е®үе…Ёзҡ„map пјҢ йҷӨдәҶдә’ж–ҘйҮҸд»ҘеӨ– пјҢ иҝҳиҝҗз”ЁдәҶеҺҹеӯҗж“ҚдҪңпјҢжүҖд»ҘеңЁиҝҷд№ӢеүҚпјҢжңүеҝ…иҰҒдәҶи§ЈдёӢ GoиҜӯиЁҖвҖ”вҖ”еҺҹеӯҗж“ҚдҪң
go1.10\src\sync\map.go
entryеҲҶдёәдёүз§Қжғ…еҶөпјҡ
д»ҺreadдёӯиҜ»еҸ–key пјҢ еҰӮжһңkeyеӯҳеңЁе°ұtryStore гҖӮ
жіЁж„ҸиҝҷйҮҢејҖе§ӢйңҖиҰҒеҠ й”ҒпјҢеӣ дёәйңҖиҰҒж“ҚдҪңdirty гҖӮ
жқЎзӣ®еңЁreadдёӯпјҢйҰ–е…ҲеҸ–ж¶Ҳж Үи®°пјҢ然еҗҺе°ҶжқЎзӣ®дҝқеӯҳеҲ°dirtyйҮҢ гҖӮпјҲеӣ дёәж Үи®°зҡ„ж•°жҚ®дёҚеңЁdirtyйҮҢпјү
жңҖеҗҺеҺҹеӯҗдҝқеӯҳvalueеҲ°жқЎзӣ®йҮҢйқўпјҢиҝҷйҮҢжіЁж„Ҹreadе’ҢdirtyйғҪжңүжқЎзӣ® гҖӮ
жҖ»з»“дёҖдёӢStoreпјҡ
иҝҷйҮҢеҸҜд»ҘзңӢеҲ°dirtyдҝқеӯҳдәҶж•°жҚ®зҡ„дҝ®ж”№пјҢйҷӨйқһеҸҜд»ҘзӣҙжҺҘеҺҹеӯҗжӣҙж–°readпјҢ继з»ӯдҝқжҢҒread clean гҖӮ
жңүдәҶд№ӢеүҚзҡ„з»ҸйӘҢпјҢеҸҜд»ҘзҢңжөӢдёӢloadжөҒзЁӢпјҡ
дёҺзҢңжөӢзҡ„ еҢәеҲ« пјҡ
з”ұдәҺж•°жҚ®дҝқеӯҳдёӨд»ҪпјҢжүҖд»ҘеҲ йҷӨиҖғиҷ‘пјҡ
е…ҲзңӢ第дәҢз§Қжғ…еҶө гҖӮеҠ й”ҒзӣҙжҺҘеҲ йҷӨdirtyж•°жҚ® гҖӮжҖқиҖғдёӢиІҢдјјжІЎд»Җд№Ҳй—®йўҳпјҢжң¬иә«е°ұжҳҜи„Ҹж•°жҚ® гҖӮ
第дёҖз§Қе’Ң第дёүз§Қжғ…еҶөе”ҜдёҖзҡ„еҢәеҲ«е°ұжҳҜжқЎзӣ®жҳҜеҗҰиў«ж Үи®° гҖӮж Үи®°д»ЈиЎЁеҲ йҷӨпјҢжүҖд»ҘзӣҙжҺҘиҝ”еӣһ гҖӮеҗҰеҲҷCASж“ҚдҪңзҪ®дёәnil гҖӮиҝҷйҮҢжҖ»ж„ҹи§үе°‘зӮ№д»Җд№ҲпјҢеӣ дёәжқЎзӣ®е…¶е®һиҝҳжҳҜеӯҳеңЁзҡ„ пјҢ иҷҪ然жҢҮй’Ҳnil гҖӮ
зңӢдәҶдёҖеңҲиІҢдјјжІЎжүҫеҲ°ж Үи®°зҡ„йҖ»иҫ‘пјҢеӣ дёәеҲ йҷӨеҸӘжҳҜе°Ҷд»–еҸҳжҲҗnil гҖӮ
д№ӢеүҚд»ҘдёәиҝҷдёӘйҖ»иҫ‘е°ұжҳҜз®ҖеҚ•зҡ„е°Ҷдёәж Үи®°зҡ„жқЎзӣ®жӢ·иҙқз»ҷdirtyпјҢзҺ°еңЁзңӢжқҘеӨ§жңүж–Үз« гҖӮ
p == nilпјҢиҜҙжҳҺжқЎзӣ®е·Із»Ҹиў«deleteдәҶпјҢCASе°Ҷд»–зҪ®дёәж Үи®°еҲ йҷӨ гҖӮ然еҗҺиҝҷдёӘжқЎзӣ®е°ұдёҚдјҡдҝқеӯҳеңЁdirtyйҮҢйқў гҖӮ
иҝҷйҮҢе…¶е®һе°ұи·ҹmissйҖ»иҫ‘дёІиө·жқҘдәҶпјҢеӣ дёәmissиҫҫеҲ°йҳҲеҖјд№ӢеҗҺпјҢdirtyдјҡе…ЁйҮҸеҸҳжҲҗreadпјҢд№ҹе°ұжҳҜиҜҙж Үи®°еҲ йҷӨеңЁиҝҷдёҖжӯҘжңҖз»ҲеҲ йҷӨ гҖӮиҝҷдёӘиҝҳжҳҜеҫҲе·§еҰҷзҡ„ гҖӮ
зңҹжӯЈзҡ„еҲ йҷӨйҖ»иҫ‘пјҡ
еҫҲз»• гҖӮгҖӮгҖӮгҖӮ
Golang 并еҸ‘иҜ»еҶҷmapе®үе…Ёй—®йўҳиҜҰи§Ј дёӢйқўе…ҲеҶҷдёҖж®өжөӢиҜ•зЁӢеәҸпјҢ然еҗҺзңӢдёӢиҝҗиЎҢз»“жһңпјҡ
иҝҗиЎҢз»“жһңпјҡ
еҸ‘з”ҹдәҶй”ҷиҜҜпјҢжҸҗзӨәпјҡfatal error: concurrent map read and map writeпјҢ map еҸ‘з”ҹдәҶеҗҢж—¶иҜ»е’ҢеҶҷдәҶпјӣ дҪҶжҳҜиҝҷдёӘй”ҷиҜҜ并дёҚжҳҜжҜҸж¬ЎиҝҗиЎҢйғҪдјҡеҮәзҺ°пјҢе°ұжҳҜжңүзҡ„ж—¶еҖҷдјҡеҮәзҺ° пјҢ жңүзҡ„ж—¶еҖҷ并дёҚдјҡеҮәзҺ°пјҢж №жҚ®з¬”иҖ…еӨҡж¬ЎиҝҗиЎҢз»“жһң(е…¶д»–дҫӢеӯҗпјҢиҜ»иҖ…еҸҜд»ҘиҮӘе·ұе°қиҜ•дёӢ)жқҘзңӢиҝҳдјҡжңүеҸҰеӨ–дёҖз§ҚжҠҘй”ҷе°ұжҳҜпјҡfatal error: concurrent map writesпјҢе°ұжҳҜmapеҸ‘з”ҹдәҶеҗҢж—¶еҶҷ пјҢ дҪҶжҳҜеҸӘжҳҜиҜ»жҳҜдёҚдјҡжңүй—®йўҳзҡ„ гҖӮе…ідәҺдёҚеҗҢзҡ„иҝҗиЎҢз»“жһңе°Ҹдјҷдјҙ们еҸҜд»ҘиҮӘе·ұеҶҷеҮ дёӘдҫӢеӯҗеҺ»жөӢиҜ•дёӢ гҖӮдёӢйқўе°ұиҝҷдёӨдёӘй”ҷиҜҜзҡ„еҸ‘з”ҹпјҢ笔иҖ…з»ҷеҮәеҰӮдёӢи§ЈйҮҠпјҡ
пјҲ1пјү fatal error: concurrent map read and map write
е°ұжҳҜеҪ“дёҖдёӘgoroutineеңЁеҶҷж•°жҚ®пјҢиҖҢеҗҢж—¶еҸҰеӨ–дёҖдёӘgoroutineиҰҒиҜ»ж•°жҚ®е°ұдјҡжҠҘй”ҷпјҢдёҚиҝҮиҝҷдёӘжҠҘй”ҷд№ҹеҫҲеҘҪзҗҶи§ЈпјҡиҝҳжІЎеҶҷе®Ңе°ұиҜ»пјҢиҜ»зҡ„ж•°жҚ®дјҡжңүй—®йўҳпјҢжҲ–иҖ…еҸҚиҝҮжқҘиҝҳжІЎиҜ»е®Ңе°ұејҖе§ӢеҶҷдәҶпјҢеҗҢж ·дјҡеҜјиҮҙиҜ»еҸ–зҡ„ж•°жҚ®жңүй—®йўҳпјӣ
пјҲ2пјү fatal error: concurrent map writes
дёӨдёӘgoroutine еҗҢж—¶еҶҷдёҖдёӘеҶ…еӯҳең°еқҖпјҢиҝҷз§Қж“ҚдҪңд№ҹжҳҜдёҚе…Ғи®ёзҡ„ пјҢ дјҡеҜјиҮҙдёҖдәӣжҜ”иҫғеҘҮжҖӘзҡ„й—®йўҳпјӣ
жҖ»дҪ“жқҘзңӢе…¶е®һе°ұжҳҜеҶҷmapзҡ„ж“ҚдҪңе’Ңе…¶д»–зҡ„иҜ»жҲ–иҖ…еҶҷеҗҢж—¶еҸ‘з”ҹдәҶ пјҢ еҜјиҮҙзҡ„жҠҘй”ҷпјҢеҒҡиҝҮеҮ е№ҙејҖеҸ‘зҡ„дәәеҸҜиғҪдјҡжғіеҲ°дҪҝз”Ёй”ҒжқҘи§ЈеҶі пјҢ жҜ”еҰӮеҶҷmapжҹҗдёӘkeyзҡ„ж—¶еҖҷ пјҢ йҖҡиҝҮй”ҒжқҘдҝқиҜҒе…¶д»–goroutineдёҚиғҪеҶҚеҜ№е…¶еҶҷжҲ–иҖ…иҜ»дәҶ гҖӮ
е®һзҺ°жҖқи·Ҝпјҡ
пјҲ1пјү еҪ“еҶҷmapзҡ„жҹҗдёӘkeyж—¶ пјҢ йҖҡиҝҮй”ҒжқҘдҝқиҜҒе…¶д»–goroutineдёҚиғҪеҶҚеҜ№е…¶еҶҷжҲ–иҖ…иҜ»дәҶ гҖӮ
пјҲ2пјү еҪ“иҜ»mapзҡ„жҹҗдёӘkeyж—¶пјҢйҖҡиҝҮй”ҒжқҘдҝқиҜҒе…¶д»–зҡ„goroutineдёҚиғҪеҶҚеҜ№е…¶еҶҷпјҢдҪҶжҳҜеҸҜд»ҘиҜ» гҖӮ
дәҺжҳҜжҲ‘们马дёҠжғіеҲ°golang зҡ„иҜ»еҶҷй”ҒиІҢдјјз¬ҰеҗҲйңҖжұӮ пјҢ дёӢйқўжқҘе®һзҺ°дёӢпјҡ
еҶҚжқҘзңӢдёӢиҝҗиЎҢз»“жһңпјҡ
еҸ‘зҺ°жІЎжңүжҠҘй”ҷдәҶпјҢ并且еӨҡж¬ЎиҝҗиЎҢзҡ„з»“жһңйғҪдёҚдјҡжҠҘй”ҷпјҢиҜҙжҳҺиҝҷдёӘж–№жі•жҳҜжңүз”Ёзҡ„пјҢдёҚиҝҮеңЁgo1.9зүҲжң¬еҗҺе°ұжңүsync.MapдәҶпјҢдёҚиҝҮиҝҷдёӘйҖӮз”ЁеңәжҷҜжҳҜиҜ»еӨҡеҶҷе°‘зҡ„еңәжҷҜпјҢеҰӮжһңеҶҷеҫҲеӨҡзҡ„иҜқж•ҲзҺҮжҜ”иҫғе·®пјҢе…·дҪ“зҡ„еҺҹеӣ еңЁиҝҷйҮҢ笔иҖ…е°ұдёҚд»Ӣз»ҚдәҶпјҢеҗҺйқўдјҡеҶҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдёӢ гҖӮ
д»ҠеӨ©зҡ„ж–Үз« е°ұеҲ°иҝҷйҮҢдәҶ пјҢ еҰӮжһңжңүдёҚеҜ№зҡ„ең°ж–№ж¬ўиҝҺе°Ҹдјҷдјҙз»ҷжҲ‘з•ҷиЁҖпјҢзңӢеҲ°дјҡеҚіж—¶еӣһеӨҚзҡ„ гҖӮ
goйқўиҜ•йўҳж•ҙзҗҶпјҲйҷ„еёҰйғЁеҲҶиҮӘе·ұзҡ„и§Јзӯ”пјүеҺҹж–ҮпјҡгҖҗгҖ‘
еҰӮжһңжңүи§Јзӯ”goиҜӯиЁҖsync.mapзҡ„дёҚеҜ№зҡ„goиҜӯиЁҖsync.mapпјҢйә»зғҰеҗ„дҪҚеңЁиҜ„и®әеҶҷеҮәжқҘ~
goзҡ„и°ғеәҰеҺҹзҗҶжҳҜеҹәдәҺGMPжЁЎеһӢпјҢGд»ЈиЎЁдёҖдёӘgoroutineпјҢдёҚйҷҗеҲ¶ж•°йҮҸgoиҜӯиЁҖsync.mapпјӣM=machineпјҢд»ЈиЎЁдёҖдёӘзәҝзЁӢпјҢжңҖеӨ§1дёҮпјҢжүҖжңүGд»»еҠЎиҝҳжҳҜеңЁMдёҠжү§иЎҢпјӣP=processorд»ЈиЎЁдёҖдёӘеӨ„зҗҶеҷЁпјҢжҜҸдёҖдёӘе…Ғи®ёзҡ„MйғҪдјҡз»‘е®ҡдёҖдёӘGпјҢй»ҳи®ӨдёҺйҖ»иҫ‘CPUж•°йҮҸзӣёзӯүпјҲйҖҡиҝҮruntime.GOMAXPROCS(runtime.NumCPU())и®ҫзҪ®пјү гҖӮ
goи°ғз”ЁиҝҮзЁӢпјҡ
еҸҜд»ҘиғҪ пјҢ д№ҹеҸҜд»ҘдёҚиғҪ гҖӮ
еӣ дёәgoеӯҳеңЁдёҚиғҪдҪҝз”Ё==еҲӨж–ӯзұ»еһӢпјҡmapгҖҒsliceпјҢеҰӮжһңstructеҢ…еҗ«иҝҷдәӣзұ»еһӢзҡ„еӯ—ж®өпјҢеҲҷдёҚиғҪжҜ”иҫғ гҖӮ
иҝҷдёӨз§Қзұ»еһӢд№ҹдёҚиғҪдҪңдёәmapзҡ„key гҖӮ
зұ»дјјж Ҳж“ҚдҪңпјҢеҗҺиҝӣе…ҲеҮә гҖӮ
еӣ дёәgoзҡ„returnжҳҜдёҖдёӘйқһеҺҹеӯҗжҖ§ж“ҚдҪң пјҢ жҜ”еҰӮиҜӯеҸҘreturn i пјҢ е®һйҷ…дёҠеҲҶдёӨжӯҘиҝӣиЎҢпјҢеҚіе°ҶiеҖјеӯҳе…Ҙж ҲдёӯдҪңдёәиҝ”еӣһеҖјпјҢ然еҗҺжү§иЎҢи·іиҪ¬пјҢиҖҢdeferзҡ„жү§иЎҢж—¶жңәжӯЈжҳҜи·іиҪ¬еүҚпјҢжүҖд»ҘиҜҙdeferжү§иЎҢж—¶иҝҳжҳҜжңүжңәдјҡж“ҚдҪңиҝ”еӣһеҖјзҡ„ гҖӮ
selectзҡ„caseзҡ„иЎЁиҫҫејҸеҝ…йЎ»жҳҜдёҖдёӘchannelзұ»еһӢпјҢжүҖжңүcaseйғҪдјҡиў«жұӮеҖјпјҢжұӮеҖјйЎәеәҸиҮӘдёҠиҖҢдёӢпјҢд»Һе·ҰиҮіеҸі гҖӮеҰӮжһңеӨҡдёӘcaseеҸҜд»Ҙе®ҢжҲҗ пјҢ еҲҷдјҡйҡҸжңәжү§иЎҢдёҖдёӘcaseпјҢеҰӮжһңжңүdefaultеҲҶж”ҜпјҢеҲҷжү§иЎҢdefaultеҲҶж”ҜиҜӯеҸҘ гҖӮеҰӮжһңиҝһdefaultйғҪжІЎжңүпјҢеҲҷselectиҜӯеҸҘдјҡдёҖзӣҙйҳ»еЎһпјҢзӣҙеҲ°иҮіе°‘жңүдёҖдёӘIOж“ҚдҪңеҸҜд»ҘиҝӣиЎҢ гҖӮ
breakе…ій”®еӯ—еҸҜи·іеҮәselectзҡ„жү§иЎҢ гҖӮ
goroutineз®ЎзҗҶгҖҒдҝЎжҒҜдј йҖ’ гҖӮcontextзҡ„ж„ҸжҖқжҳҜдёҠдёӢж–ҮпјҢеңЁзәҝзЁӢгҖҒеҚҸзЁӢдёӯйғҪжңүиҝҷдёӘжҰӮеҝөпјҢе®ғжҢҮзҡ„жҳҜзЁӢеәҸеҚ•е…ғзҡ„дёҖдёӘиҝҗиЎҢзҠ¶жҖҒгҖҒзҺ°еңәгҖҒеҝ«з…§пјҢеҢ…еҗ« гҖӮcontextеңЁеӨҡдёӘgoroutineдёӯжҳҜ并еҸ‘е®үе…Ёзҡ„ гҖӮ
еә”з”ЁеңәжҷҜпјҡ
дҫӢеӯҗеҸӮиҖғпјҡ
waitgroup
channel
lenпјҡеҲҮзүҮзҡ„й•ҝеәҰпјҢи®ҝй—®ж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјҢgoзҡ„sliceеә•еұӮжҳҜеҜ№ж•°з»„зҡ„еј•з”Ё гҖӮ
capпјҡеҲҮзүҮзҡ„е®№йҮҸпјҢжү©е®№жҳҜд»ҘиҝҷдёӘеҖјдёәж ҮеҮҶ гҖӮй»ҳи®Өжү©е®№жҳҜ2еҖҚпјҢеҪ“иҫҫеҲ°1024зҡ„й•ҝеәҰеҗҺ пјҢ жҢү1.25еҖҚ гҖӮ
жү©е®№пјҡжҜҸж¬Ўжү©е®№sliceеә•еұӮйғҪе°Ҷе…ҲеҲҶй…Қж–°зҡ„е®№йҮҸзҡ„еҶ…еӯҳз©әй—ҙпјҢеҶҚе°ҶиҖҒзҡ„ж•°з»„жӢ·иҙқеҲ°ж–°зҡ„еҶ…еӯҳз©әй—ҙпјҢеӣ дёәиҝҷдёӘж“ҚдҪңдёҚжҳҜ并еҸ‘е®үе…Ёзҡ„ гҖӮжүҖд»Ҙ并еҸ‘иҝӣиЎҢappendж“ҚдҪңпјҢиҜ»еҲ°еҶ…еӯҳдёӯзҡ„иҖҒж•°з»„еҸҜиғҪдёәеҗҢдёҖдёӘпјҢжңҖз»ҲеҜјиҮҙappendзҡ„ж•°жҚ®дёўеӨұ гҖӮ
е…ұдә«пјҡsliceзҡ„еә•еұӮжҳҜеҜ№ж•°з»„зҡ„еј•з”ЁпјҢеӣ жӯӨеҰӮжһңдёӨдёӘеҲҮзүҮеј•з”ЁдәҶеҗҢдёҖдёӘж•°з»„зүҮж®ө пјҢ е°ұдјҡеҪўжҲҗе…ұдә«еә•еұӮж•°з»„ гҖӮеҪ“sliecеҸ‘з”ҹеҶ…еӯҳзҡ„йҮҚж–°еҲҶй…ҚпјҲеҰӮжү©е®№пјүж—¶ пјҢ дјҡеҜ№е…ұдә«иҝӣиЎҢйҡ”ж–ӯ гҖӮиҜҰз»Ҷи§ҒдёӢйқўдҫӢеӯҗпјҡ
make([]Type,len,cap)
mapзҡ„еә•еұӮжҳҜhash table(hmapзұ»еһӢ)пјҢеҜ№keyеҖјиҝӣиЎҢдәҶhashпјҢ并е°Ҷз»“жһңзҡ„дҪҺе…«дҪҚз”ЁдәҺзЎ®е®ҡkey/valueеӯҳеңЁдәҺе“ӘдёӘbucketпјҲbmapзұ»еһӢпјү гҖӮеҶҚе°Ҷй«ҳе…«дҪҚдёҺbucketзҡ„tophashиҝӣиЎҢдҫқж¬ЎжҜ”иҫғпјҢзЎ®е®ҡжҳҜеҗҰеӯҳеңЁ гҖӮеҮәзҺ°hashеҶІж’һж—¶пјҢдјҡйҖҡиҝҮbucketзҡ„overflowжҢҮеҗ‘еҸҰдёҖдёӘbucketпјҢеҪўжҲҗдёҖдёӘеҚ•еҗ‘й“ҫиЎЁ гҖӮжҜҸдёӘbucketеӯҳеӮЁ8дёӘй”®еҖјеҜ№ гҖӮ
еҰӮжһңиҰҒе®һзҺ°mapзҡ„йЎәеәҸиҜ»еҸ– пјҢ йңҖиҰҒдҪҝз”ЁдёҖдёӘsliceжқҘеӯҳеӮЁmapзҡ„key并жҢүз…§йЎәеәҸиҝӣиЎҢжҺ’еәҸ гҖӮ
еҲ©з”ЁmapпјҢеҰӮжһңиҰҒжұӮ并еҸ‘е®үе…Ё пјҢ е°ұз”Ёsync.map
иҰҒжіЁж„ҸдёӢsetдёӯзҡ„deleteеҮҪж•°йңҖиҰҒдҪҝз”Ёdelete(map) жқҘе®һзҺ°пјҢдҪҶжҳҜиҝҷдёӘ并дёҚдјҡйҮҠж”ҫеҶ…еӯҳпјҢйҷӨйқһvalueд№ҹжҳҜдёҖдёӘеӯҗmap гҖӮеҪ“иҝӣиЎҢеӨҡж¬ЎdeleteеҗҺпјҢеҸҜд»ҘдҪҝз”ЁmakeжқҘйҮҚе»әmap гҖӮ
дҪҝз”Ёsync.MapжқҘз®ЎзҗҶtopicпјҢз”ЁchannelжқҘеҒҡйҳҹеҲ— гҖӮ
еҸӮиҖғпјҡ
еӨҡи·ҜеҪ’并法:
pre class="vditor-reset" placeholder="" contenteditable="true" spellcheck="false"p data-block="0"(1)еҒҮи®ҫжңүKи·Ҝa href=""ж•°жҚ®жөҒ/aпјҢжөҒеҶ…йғЁжҳҜжңүеәҸзҡ„пјҢдё”жөҒй—ҙеҗҢдёәеҚҮеәҸжҲ–йҷҚеәҸпјӣ
/pp data-block="0"(2)йҰ–е…ҲиҜ»еҸ–жҜҸдёӘжөҒзҡ„第дёҖдёӘж•°пјҢеҰӮжһңе·Із»ҸEOFпјҢpassпјӣ
/pp data-block="0"(3)е°Ҷжңүж•Ҳзҡ„k(kеҸҜиғҪе°ҸдәҺK)дёӘж•°жҜ”иҫғпјҢйҖүеҮәжңҖе°Ҹзҡ„йӮЈи·ҜminkпјҢиҫ“еҮә пјҢ иҜ»еҸ–minkзҡ„дёӢдёҖдёӘпјӣ
/pp data-block="0"(4)зӣҙеҲ°жүҖжңүKи·ҜйғҪEOF гҖӮ
/p/pre
еҒҮи®ҫж–Ү件еҸҲ1дёӘGпјҢеҶ…еӯҳеҸӘжңү256MпјҢж— жі•е°Ҷ1дёӘGзҡ„ж–Ү件全йғЁиҜ»еҲ°еҶ…еӯҳиҝӣиЎҢжҺ’еәҸ гҖӮ
第дёҖжӯҘпјҡ
еҸҜд»ҘеҲҶдёә10ж®өиҜ»еҸ–пјҢжҜҸж®өиҜ»еҸ–100Mзҡ„ж•°жҚ®е№¶жҺ’еәҸеҘҪеҶҷе…ҘзЎ¬зӣҳ гҖӮ
еҒҮи®ҫеҶҷе…ҘеҗҺзҡ„ж–Ү件дёәA,BпјҢC...10
第дәҢжӯҘ:
е°ҶA пјҢ B,C...10зҡ„第дёҖдёӘеӯ—з¬ҰжӢҝеҮәжқҘ пјҢ еҜ№иҝҷ10дёӘеӯ—з¬ҰиҝӣиЎҢжҺ’еәҸпјҢ并е°Ҷз»“жһңеҶҷе…ҘзЎ¬зӣҳпјҢеҗҢж—¶и®°еҪ•иў«еҶҷе…Ҙзҡ„еӯ—з¬Ұзҡ„ж–Ү件жҢҮй’ҲP гҖӮ
第дёүжӯҘпјҡ
е°ҶеҲҡеҲҡжҺ’еәҸеҘҪзҡ„9дёӘеӯ—з¬ҰеҶҚеҠ дёҠд»ҺжҢҮй’ҲPиҜ»еҸ–еҲ°зҡ„P 1дҪҚж•°жҚ®иҝӣиЎҢжҺ’еәҸпјҢ并еҶҷе…ҘзЎ¬зӣҳ гҖӮ
йҮҚеӨҚдәҢгҖҒдёүжӯҘйӘӨ гҖӮ
goж–Ү件иҜ»еҶҷеҸӮиҖғпјҡ
дҝқиҜҒжҺ’еәҸеүҚдёӨдёӘзӣёзӯүзҡ„ж•°е…¶еңЁеәҸеҲ—зҡ„еүҚеҗҺдҪҚзҪ®йЎәеәҸе’ҢжҺ’еәҸеҗҺе®ғ们дёӨдёӘзҡ„еүҚеҗҺдҪҚзҪ®йЎәеәҸзӣёеҗҢзҡ„жҺ’еәҸеҸ«зЁіе®ҡжҺ’еәҸ гҖӮ
еҝ«йҖҹжҺ’еәҸгҖҒеёҢе°”жҺ’еәҸгҖҒе ҶжҺ’еәҸгҖҒзӣҙжҺҘйҖүжӢ©жҺ’еәҸдёҚжҳҜзЁіе®ҡзҡ„жҺ’еәҸз®—жі• гҖӮ
еҹәж•°жҺ’еәҸгҖҒеҶ’жіЎжҺ’еәҸгҖҒзӣҙжҺҘжҸ’е…ҘжҺ’еәҸгҖҒжҠҳеҚҠжҸ’е…ҘжҺ’еәҸгҖҒеҪ’并жҺ’еәҸжҳҜзЁіе®ҡзҡ„жҺ’еәҸз®—жі• гҖӮ
еҸӮиҖғпјҡ
headеҸӘиҜ·жұӮйЎөйқўзҡ„йҰ–йғЁ гҖӮеӨҡз”ЁжқҘеҲӨж–ӯзҪ‘йЎөжҳҜеҗҰиў«дҝ®ж”№е’Ңи¶…й“ҫжҺҘзҡ„жңүж•ҲжҖ§ гҖӮ
getиҜ·жұӮйЎөйқўдҝЎжҒҜпјҢ并иҝ”еӣһе®һдҫӢзҡ„дё»дҪ“ гҖӮ
еҸӮиҖғ:
401пјҡжңӘжҺҲжқғзҡ„и®ҝй—® гҖӮ
403: жӢ’з»қи®ҝй—® гҖӮ
жҷ®йҖҡзҡ„httpиҝһжҺҘжҳҜе®ўжҲ·з«ҜиҝһжҺҘдёҠжңҚеҠЎз«ҜпјҢ然еҗҺз»“жқҹиҜ·жұӮеҗҺпјҢз”ұе®ўжҲ·з«ҜжҲ–иҖ…жңҚеҠЎз«ҜиҝӣиЎҢhttpиҝһжҺҘзҡ„е…ій—ӯ гҖӮдёӢж¬ЎеҶҚеҸ‘йҖҒиҜ·жұӮзҡ„ж—¶еҖҷпјҢе®ўжҲ·з«ҜеҶҚеҸ‘иө·дёҖдёӘиҝһжҺҘпјҢдј йҖҒж•°жҚ®пјҢе…ій—ӯиҝһжҺҘ гҖӮиҝҷд№ҲдёӘжөҒзЁӢеҸҚеӨҚ гҖӮдҪҶжҳҜдёҖж—Ұе®ўжҲ·з«ҜеҸ‘йҖҒconnection:keep-aliveеӨҙз»ҷжңҚеҠЎз«ҜпјҢдё”жңҚеҠЎз«Ҝд№ҹжҺҘеҸ—иҝҷдёӘkeep-aliveзҡ„иҜқ пјҢ дёӨиҫ№еҜ№дёҠжҡ—еҸ·пјҢиҝҷдёӘиҝһжҺҘе°ұеҸҜд»ҘеӨҚз”ЁдәҶпјҢдёҖдёӘhttpеӨ„зҗҶе®Ңд№ӢеҗҺпјҢеҸҰеӨ–дёҖдёӘhttpж•°жҚ®зӣҙжҺҘд»ҺиҝҷдёӘиҝһжҺҘиө°дәҶ гҖӮеҮҸе°‘ж–°е»әе’Ңж–ӯејҖTCPиҝһжҺҘзҡ„ж¶ҲиҖ— гҖӮиҝҷдёӘеҸҜд»ҘеңЁNginxи®ҫзҪ® пјҢ
иҝҷдёӘkeepalive_timoutж—¶й—ҙеҖјж„Ҹе‘ізқҖпјҡдёҖдёӘhttpдә§з”ҹзҡ„tcpиҝһжҺҘеңЁдј йҖҒе®ҢжңҖеҗҺдёҖдёӘе“Қеә”еҗҺпјҢиҝҳйңҖиҰҒholdдҪҸkeepalive_timeoutз§’еҗҺ пјҢ жүҚејҖе§Ӣе…ій—ӯиҝҷдёӘиҝһжҺҘ гҖӮ
зү№еҲ«жіЁж„ҸTCPеұӮзҡ„keep aliveе’ҢhttpдёҚжҳҜдёҖдёӘж„ҸжҖқ гҖӮTCPзҡ„жҳҜжҢҮпјҡtcpиҝһжҺҘе»әз«ӢеҗҺпјҢеҰӮжһңе®ўжҲ·з«ҜеҫҲй•ҝдёҖж®өж—¶й—ҙдёҚеҸ‘йҖҒж¶ҲжҒҜпјҢеҪ“иҝһжҺҘеҫҲд№…жІЎжңү收еҲ°жҠҘж–ҮпјҢtcpдјҡдё»еҠЁеҸ‘йҖҒдёҖдёӘдёәз©әзҡ„жҠҘж–ҮпјҲдҫҰжөӢеҢ…пјүз»ҷеҜ№ж–№пјҢеҰӮжһңеҜ№ж–№ж”¶еҲ°дәҶ并且еӣһеӨҚдәҶпјҢиҜҒжҳҺеҜ№ж–№иҝҳеңЁ гҖӮеҰӮжһңеҜ№ж–№жІЎжңүжҠҘж–Үиҝ”еӣһпјҢйҮҚиҜ•еӨҡж¬Ўд№ӢеҗҺеҲҷзЎ®и®ӨиҝһжҺҘдёўеӨұпјҢж–ӯејҖиҝһжҺҘ гҖӮ
tcpзҡ„keep aliveеҸҜйҖҡиҝҮ
net.ipv4.tcp_keepalive_intvl = 75// еҪ“жҺўжөӢжІЎжңүзЎ®и®Өж—¶пјҢйҮҚж–°еҸ‘йҖҒжҺўжөӢзҡ„йў‘еәҰ гҖӮзјәзңҒжҳҜ75з§’ гҖӮ
net.ipv4.tcp_keepalive_probes = 9 //еңЁи®Өе®ҡиҝһжҺҘеӨұж•Ҳд№ӢеүҚ пјҢ еҸ‘йҖҒеӨҡе°‘дёӘTCPзҡ„keepaliveжҺўжөӢеҢ… гҖӮзјәзңҒеҖјжҳҜ9 гҖӮиҝҷдёӘеҖјд№ҳд»Ҙtcp_keepalive_intvlд№ӢеҗҺеҶіе®ҡдәҶпјҢдёҖдёӘиҝһжҺҘеҸ‘йҖҒдәҶkeepaliveд№ӢеҗҺеҸҜд»ҘжңүеӨҡе°‘ж—¶й—ҙжІЎжңүеӣһеә”
net.ipv4.tcp_keepalive_time = 7200 //еҪ“keepaliveиө·з”Ёзҡ„ж—¶еҖҷпјҢTCPеҸ‘йҖҒkeepaliveж¶ҲжҒҜзҡ„йў‘еәҰ гҖӮзјәзңҒжҳҜ2е°Ҹж—¶ гҖӮдёҖиҲ¬и®ҫзҪ®дёә30еҲҶй’ҹ1800
дҝ®ж”№пјҡ
еҸҜд»Ҙ
tcpжҳҜйқўеҗ‘иҝһжҺҘзҡ„пјҢupdжҳҜж— иҝһжҺҘзҠ¶жҖҒзҡ„ гҖӮ
udpзӣёжҜ”tcpжІЎжңүе»әз«ӢиҝһжҺҘзҡ„иҝҮзЁӢпјҢжүҖд»Ҙжӣҙеҝ«пјҢеҗҢж—¶д№ҹжӣҙе®үе…ЁпјҢдёҚе®№жҳ“иў«ж”»еҮ» гҖӮupdжІЎжңүйҳ»еЎһжҺ§еҲ¶пјҢеӣ жӯӨеҮәзҺ°зҪ‘з»ңйҳ»еЎһдёҚдјҡдҪҝжәҗдё»жңәзҡ„еҸ‘йҖҒж•ҲзҺҮйҷҚдҪҺ гҖӮupdж”ҜжҢҒдёҖеҜ№еӨҡ пјҢ еӨҡеҜ№еӨҡзӯүпјҢtcpжҳҜзӮ№еҜ№зӮ№дј иҫ“ гҖӮtcpйҰ–йғЁејҖй”Җ20еӯ—иҠӮпјҢudp8еӯ—иҠӮ гҖӮ
udpдҪҝз”ЁеңәжҷҜпјҡи§Ҷйў‘йҖҡиҜқгҖҒimиҒҠеӨ©зӯү гҖӮ
time-waitиЎЁзӨәе®ўжҲ·з«Ҝзӯүеҫ…жңҚеҠЎз«Ҝиҝ”еӣһе…ій—ӯдҝЎжҒҜзҡ„зҠ¶жҖҒпјҢclosed_waitиЎЁзӨәжңҚеҠЎз«Ҝеҫ—зҹҘе®ўжҲ·з«ҜжғіиҰҒе…ій—ӯиҝһжҺҘ пјҢ иҝӣе…ҘеҚҠе…ій—ӯзҠ¶жҖҒ并иҝ”еӣһдёҖж®өTCPжҠҘж–Ү гҖӮ
time-waitдҪңз”Ёпјҡ
и§ЈеҶіеҠһжі•пјҡ
close_wait:
иў«еҠЁе…ій—ӯпјҢйҖҡеёёжҳҜз”ұдәҺе®ўжҲ·з«Ҝеҝҳи®°е…ій—ӯtcpиҝһжҺҘеҜјиҮҙ гҖӮ
ж №жҚ®дёҡеҠЎжқҘе•Ҡ~
йҮҚиҰҒжҢҮж ҮжҳҜcardinalityпјҲдёҚйҮҚеӨҚж•°йҮҸпјүпјҢиҝҷдёӘж•°йҮҸ/жҖ»иЎҢж•°еҰӮжһңиҝҮ?гҖӮг„Үй№ҳоҸһ?пјүд»ЈиЎЁзҙўеј•еҹәжң¬жІЎж„Ҹд№үпјҢжҜ”еҰӮsexжҖ§еҲ«иҝҷз§Қ гҖӮ
еҸҰеӨ–жҹҘиҜўдёҚиҰҒдҪҝз”Ёselect * пјҢ ж №жҚ®selectзҡ„жқЎд»¶ whereжқЎд»¶еҒҡз»„еҗҲзҙўеј•пјҢе°ҪйҮҸе®һзҺ°иҰҶзӣ–зҙўеј•пјҢйҒҝе…ҚеӣһиЎЁ гҖӮ
еғөе°ёиҝӣзЁӢпјҡ
еҚіеӯҗиҝӣзЁӢе…ҲдәҺзҲ¶иҝӣзЁӢйҖҖеҮәеҗҺ пјҢ еӯҗиҝӣзЁӢзҡ„PCBйңҖиҰҒе…¶зҲ¶иҝӣзЁӢйҮҠж”ҫпјҢдҪҶжҳҜзҲ¶иҝӣзЁӢ并没жңүйҮҠж”ҫеӯҗиҝӣзЁӢзҡ„PCBпјҢиҝҷж ·зҡ„еӯҗиҝӣзЁӢе°ұз§°дёәеғөе°ёиҝӣзЁӢпјҢеғөе°ёиҝӣзЁӢе®һйҷ…дёҠжҳҜдёҖдёӘе·Із»Ҹжӯ»жҺүзҡ„иҝӣзЁӢ гҖӮ
еӯӨе„ҝиҝӣзЁӢпјҡ
дёҖдёӘзҲ¶иҝӣзЁӢйҖҖеҮәпјҢиҖҢе®ғзҡ„дёҖдёӘжҲ–еӨҡдёӘеӯҗиҝӣзЁӢиҝҳеңЁиҝҗиЎҢ пјҢ йӮЈд№ҲйӮЈдәӣеӯҗиҝӣзЁӢе°ҶжҲҗдёәеӯӨе„ҝиҝӣзЁӢ гҖӮеӯӨе„ҝиҝӣзЁӢе°Ҷиў«initиҝӣзЁӢ(иҝӣзЁӢеҸ·дёә1)жүҖ收养пјҢ并з”ұinitиҝӣзЁӢеҜ№е®ғ们е®ҢжҲҗзҠ¶жҖҒ收йӣҶе·ҘдҪң гҖӮ
еӯҗиҝӣзЁӢжӯ»дәЎйңҖиҰҒзҲ¶иҝӣзЁӢжқҘеӨ„зҗҶпјҢйӮЈд№Ҳж„Ҹе‘ізқҖжӯЈеёёзҡ„иҝӣзЁӢеә”иҜҘжҳҜеӯҗиҝӣзЁӢе…ҲдәҺзҲ¶иҝӣзЁӢжӯ»дәЎ гҖӮеҪ“зҲ¶иҝӣзЁӢе…ҲдәҺеӯҗиҝӣзЁӢжӯ»дәЎж—¶пјҢеӯҗиҝӣзЁӢжӯ»дәЎж—¶жІЎзҲ¶иҝӣзЁӢеӨ„зҗҶ пјҢ иҝҷдёӘжӯ»дәЎзҡ„еӯҗиҝӣзЁӢе°ұжҳҜеӯӨе„ҝиҝӣзЁӢ гҖӮ
дҪҶеӯӨе„ҝиҝӣзЁӢдёҺеғөе°ёиҝӣзЁӢдёҚеҗҢзҡ„жҳҜпјҢз”ұдәҺзҲ¶иҝӣзЁӢе·Із»Ҹжӯ»дәЎпјҢзі»з»ҹдјҡеё®еҠ©зҲ¶иҝӣзЁӢеӣһ收еӨ„зҗҶеӯӨе„ҝиҝӣзЁӢ гҖӮжүҖд»ҘеӯӨе„ҝиҝӣзЁӢе®һйҷ…дёҠжҳҜдёҚеҚ з”Ёиө„жәҗзҡ„пјҢеӣ дёәе®ғз»Ҳ究жҳҜиў«зі»з»ҹеӣһ收дәҶ гҖӮдёҚдјҡеғҸеғөе°ёиҝӣзЁӢйӮЈж ·еҚ з”ЁID,жҚҹе®іиҝҗиЎҢзі»з»ҹ гҖӮ
еҺҹж–Үй“ҫжҺҘпјҡ
дә§з”ҹжӯ»й”Ғзҡ„еӣӣдёӘеҝ…иҰҒжқЎд»¶пјҡ
пјҲ1пјү дә’ж–ҘжқЎд»¶пјҡдёҖдёӘиө„жәҗжҜҸж¬ЎеҸӘиғҪиў«дёҖдёӘиҝӣзЁӢдҪҝз”Ё гҖӮ
пјҲ2пјү иҜ·жұӮдёҺдҝқжҢҒжқЎд»¶пјҡдёҖдёӘиҝӣзЁӢеӣ иҜ·жұӮиө„жәҗиҖҢйҳ»еЎһж—¶ пјҢ еҜ№е·ІиҺ·еҫ—зҡ„иө„жәҗдҝқжҢҒдёҚж”ҫ гҖӮ
пјҲ3пјү дёҚеүҘеӨәжқЎд»¶пјҡиҝӣзЁӢе·ІиҺ·еҫ—зҡ„иө„жәҗпјҢеңЁжң«дҪҝз”Ёе®Ңд№ӢеүҚ пјҢ дёҚиғҪејәиЎҢеүҘеӨә гҖӮ
пјҲ4пјү еҫӘзҺҜзӯүеҫ…жқЎд»¶пјҡиӢҘе№ІиҝӣзЁӢд№Ӣй—ҙеҪўжҲҗдёҖз§ҚеӨҙе°ҫзӣёжҺҘзҡ„еҫӘзҺҜзӯүеҫ…иө„жәҗе…ізі» гҖӮ
йҒҝе…Қж–№жі•пјҡ
з«ҜеҸЈеҚ з”Ёпјҡlsof -i:з«ҜеҸЈеҸ·жҲ–иҖ… nestat
cpuгҖҒеҶ…еӯҳеҚ з”Ёпјҡtop
еҸ‘йҖҒдҝЎеҸ·пјҡkill -l еҲ—еҮәжүҖжңүдҝЎеҸ·пјҢ然еҗҺз”Ё kill [дҝЎеҸ·еҸҳеҢ–] [иҝӣзЁӢеҸ·]жқҘжү§иЎҢ гҖӮеҰӮkill -9 453 гҖӮејәеҲ¶жқҖжӯ»453иҝӣзЁӢ
git log:жҹҘзңӢжҸҗдәӨи®°еҪ•
git diff пјҡжҹҘзңӢеҸҳжӣҙи®°еҪ•
git mergeпјҡзӣ®ж ҮеҲҶж”Ҝж”№еҸҳпјҢиҖҢжәҗеҲҶж”ҜдҝқжҢҒеҺҹж · гҖӮдјҳзӮ№пјҡдҝқз•ҷжҸҗдәӨеҺҶеҸІпјҢдҝқз•ҷеҲҶж”Ҝз»“жһ„ гҖӮдҪҶдјҡжңүеӨ§йҮҸзҡ„mergeи®°еҪ•
git rebaseпјҡе°Ҷдҝ®ж”№жӢјжҺҘеҲ°жңҖж–° пјҢ еӨҚжқӮзҡ„и®°еҪ•еҸҳеҫ—дјҳйӣ… пјҢ еҚ•дёӘж“ҚдҪңеҸҳеҫ—(revert)еҫҲз®ҖеҚ•пјӣзјәзӮ№пјҡ
git revert:еҸҚеҒҡжҢҮе®ҡзүҲжң¬пјҢдјҡж–°з”ҹжҲҗдёҖдёӘзүҲжң¬
git reset:йҮҚзҪ®еҲ°жҹҗдёӘзүҲжң¬пјҢдёӯй—ҙзүҲжң¬е…ЁйғЁдёўеӨұ
etcdгҖҒConsul
pprof
иҠӮзңҒз©әй—ҙпјҲйқһеҸ¶еӯҗиҠӮзӮ№дёҚеӯҳеӮЁж•°жҚ®пјҢзӣёеҜ№b treeзҡ„дјҳеҠҝпјүпјҢеҮҸе°‘I/Oж¬Ўж•°пјҲиҠӮзңҒзҡ„з©әй—ҙе…ЁйғЁеӯҳжҢҮй’Ҳең°еқҖпјҢи®©ж ‘еҸҳзҡ„зҹ®иғ–пјүпјҢиҢғеӣҙжҹҘжүҫж–№дҫҝпјҲзӣёеҜ№hashзҡ„дјҳеҠҝпјү гҖӮ
explain
е…¶д»–зҡ„и§Ғпјҡ
runtime2.go дёӯе…ідәҺ p зҡ„е®ҡд№үпјҡ е…¶дёӯ runnext жҢҮй’ҲеҶіе®ҡдәҶдёӢдёҖдёӘиҰҒиҝҗиЎҢзҡ„ gпјҢж №жҚ®иӢұж–Үзҡ„жіЁйҮҠеӨ§иҮҙж„ҸжҖқжҳҜиҜҙпјҡ
жүҖд»ҘеҪ“и®ҫзҪ® runtime.GOMAXPROCS(1) ж—¶пјҢжӯӨж—¶еҸӘжңүдёҖдёӘ P пјҢ еҲӣе»әзҡ„ g дҫқж¬ЎеҠ е…Ҙ P пјҢ еҪ“жңҖеҗҺдёҖдёӘеҚі i==9 ж—¶ пјҢ еҠ е…Ҙзҡ„жңҖеҗҺ дёҖдёӘ g е°Ҷдјҡ继жүҝеҪ“еүҚдё» goroutinue зҡ„еү©дҪҷж—¶й—ҙзүҮ继з»ӯжү§иЎҢпјҢжүҖд»Ҙдјҡе…Ҳиҫ“еҮә 9 пјҢ д№ӢеҗҺеҶҚдҫқж¬Ўжү§иЎҢ P йҳҹеҲ—дёӯе…¶е®ғзҡ„ g гҖӮ
ж–№жі•дёҖпјҡ
ж–№жі•дәҢпјҡ
[еӣҫзүҮдёҠдј еӨұиҙҘ...(image-4ef445-1594976286098)]
ж–№жі•1пјҡto_daysпјҢиҝ”еӣһз»ҷзҡ„ж—Ҙжңҹд»Һ0ејҖе§Ӣз®—зҡ„еӨ©ж•° гҖӮ
ж–№жі•2пјҡdata_add гҖӮеҗ‘ж—Ҙжңҹж·»еҠ жҢҮе®ҡж—¶й—ҙй—ҙйҡ”
[еӣҫзүҮдёҠдј еӨұиҙҘ...(image-b67b10-1594976286098)]
Golangдёӯsync.Mapзҡ„е®һзҺ°еҺҹзҗҶеүҚйқўпјҢжҲ‘们讲дәҶmapзҡ„з”Ёжі•д»ҘеҸҠеҺҹзҗҶ Golangдёӯmapзҡ„е®һзҺ°еҺҹзҗҶпјҢдҪҶжҲ‘们зҹҘйҒ“пјҢmapеңЁе№¶еҸ‘иҜ»еҶҷзҡ„жғ…еҶөдёӢжҳҜдёҚе®үе…Ё гҖӮйңҖиҰҒ并еҸ‘иҜ»еҶҷж—¶пјҢдёҖиҲ¬зҡ„еҒҡжі•жҳҜеҠ й”ҒпјҢдҪҶиҝҷж ·жҖ§иғҪ并дёҚй«ҳпјҢGoиҜӯиЁҖеңЁ 1.9 зүҲжң¬дёӯжҸҗдҫӣдәҶдёҖз§Қж•ҲзҺҮиҫғй«ҳзҡ„并еҸ‘е®үе…Ёзҡ„ sync.MapпјҢд»ҠеӨ©пјҢжҲ‘们е°ұжқҘи®Іи®І sync.Mapзҡ„з”Ёжі•д»ҘеҸҠеҺҹзҗҶ
sync.MapдёҺmapдёҚеҗҢпјҢдёҚжҳҜд»ҘиҜӯиЁҖеҺҹз”ҹеҪўжҖҒжҸҗдҫӣпјҢиҖҢжҳҜеңЁ sync еҢ…дёӢзҡ„зү№ж®Ҡз»“жһ„пјҡ
жҲ‘们дёӢжқҘзңӢдёӢsync.Mapз»“жһ„дҪ“
з»“жһ„дҪ“д№Ӣй—ҙзҡ„е…ізі»еҰӮдёӢеӣҫжүҖзӨәпјҡ
жҖ»з»“дёҖдёӢпјҡ
Loadж–№жі•жҜ”иҫғз®ҖеҚ•пјҢжҖ»з»“дёҖдёӢпјҡ
жҖ»з»“еҰӮдёӢпјҡ
Go Map дёәд»Җд№ҲжҳҜйқһзәҝзЁӢе®үе…Ёзҡ„пјҹ Go map й»ҳи®ӨжҳҜ并еҸ‘дёҚе®үе…Ёзҡ„ пјҢ еҗҢж—¶еҜ№ map иҝӣиЎҢ并еҸ‘иҜ»еҶҷзҡ„ж—¶ пјҢ зЁӢеәҸдјҡ panic пјҢ еҺҹеӣ еҰӮдёӢпјҡGo е®ҳж–№з»ҸиҝҮй•ҝж—¶й—ҙзҡ„и®Ёи®әпјҢи®Өдёә map йҖӮй…Қзҡ„еңәжҷҜеә”иҜҘжҳҜз®ҖеҚ•зҡ„пјҲдёҚйңҖиҰҒд»ҺеӨҡдёӘ gorountine дёӯиҝӣиЎҢе®үе…Ёи®ҝй—®зҡ„пјүпјҢиҖҢдёҚжҳҜдёәдәҶе°ҸйғЁеҲҶжғ…еҶөпјҲ并еҸ‘и®ҝй—®пјүпјҢеҜјиҮҙеӨ§йғЁеҲҶзЁӢеәҸд»ҳеҮәй”Ғзҡ„д»Јд»·пјҢеӣ жӯӨеҶіе®ҡдәҶдёҚж”ҜжҢҒ гҖӮ
并еҸ‘иҜ»еҶҷеҸҜиғҪеј•еҸ‘зҡ„й—®йўҳ
дҪҝз”Ёsync.RWMutexи§ЈеҶіе№¶еҸ‘иҜ»еҶҷзҡ„й—®йўҳ
дҪҝз”Ё sync.Map и§ЈеҶіе№¶еҸ‘иҜ»еҶҷзҡ„й—®йўҳ
е®һйҷ…дёҠпјҢ sync.Mapд№ҹжҳҜйҖҡиҝҮеҠ й”Ғзҡ„ж–№ејҸе®һзҺ°е№¶еҸ‘е®үе…Ёзҡ„пјҢsync.Mapжәҗз Ғзҡ„ж•°жҚ®з»“жһ„еҰӮдёӢпјҡ
е°ұеғҸе®ҳж–№иҖғиҷ‘зҡ„йӮЈж ·пјҢжҲ‘们еңЁдҪҝз”Ёдёӯ пјҢ еә”е°ҪйҮҸйҒҝе…ҚеҜ№ Map иҝӣиЎҢ并еҸ‘иҜ»еҶҷ пјҢ е°қиҜ•йҖҡиҝҮе…¶д»–ж–№ејҸи§ЈеҶій—®йўҳ пјҢ еҰӮж•°жҚ®и§ЈиҖҰгҖҒеҲҶеёғжү§иЎҢгҖҒеҠЁжҖҒ规еҲ’зӯү пјҢ зңҹзҡ„йңҖиҰҒ并еҸ‘иҜ»еҶҷж—¶пјҢдёәйҒҝе…Қдә§з”ҹ并еҸ‘иҜ»еҶҷзҡ„й—®йўҳпјҢиҜ·дҪҝз”Ёй”Ғзҡ„жңәеҲ¶иҝӣиЎҢжҺ§еҲ¶
еҪ»еә•зҗҶи§ЈGolang Map жң¬ж–Үзӣ®еҪ•еҰӮдёӢпјҢйҳ…иҜ»жң¬ж–ҮеҗҺпјҢе°ҶдёҖзҪ‘жү“е°ҪдёӢйқўGolang Mapзӣёе…ійқўиҜ•йўҳ
Goдёӯзҡ„mapжҳҜдёҖдёӘжҢҮй’ҲпјҢеҚ з”Ё8дёӘеӯ—иҠӮпјҢжҢҮеҗ‘hmapз»“жһ„дҪ“;жәҗз Ғ src/runtime/map.go дёӯеҸҜд»ҘзңӢеҲ°mapзҡ„еә•еұӮз»“жһ„
жҜҸдёӘmapзҡ„еә•еұӮз»“жһ„жҳҜhmapпјҢhmapеҢ…еҗ«иӢҘе№ІдёӘз»“жһ„дёәbmapзҡ„bucketж•°з»„ гҖӮжҜҸдёӘbucketеә•еұӮйғҪйҮҮз”Ёй“ҫиЎЁз»“жһ„ гҖӮжҺҘдёӢжқҘпјҢжҲ‘们жқҘиҜҰз»ҶзңӢдёӢmapзҡ„з»“жһ„
bmapе°ұжҳҜжҲ‘们常иҜҙзҡ„вҖңжЎ¶вҖқпјҢдёҖдёӘжЎ¶йҮҢйқўдјҡжңҖеӨҡиЈ… 8 дёӘ keyпјҢиҝҷдәӣ key д№ӢжүҖд»ҘдјҡиҗҪе…ҘеҗҢдёҖдёӘжЎ¶пјҢжҳҜеӣ дёәе®ғ们з»ҸиҝҮе“ҲеёҢи®Ўз®—еҗҺпјҢе“ҲеёҢз»“жһңжҳҜвҖңдёҖзұ»вҖқзҡ„пјҢе…ідәҺkeyзҡ„е®ҡдҪҚжҲ‘们еңЁmapзҡ„жҹҘиҜўе’ҢжҸ’е…ҘдёӯиҜҰз»ҶиҜҙжҳҺ гҖӮеңЁжЎ¶еҶ…пјҢеҸҲдјҡж №жҚ® key и®Ўз®—еҮәжқҘзҡ„ hash еҖјзҡ„й«ҳ 8 дҪҚжқҘеҶіе®ҡ key еҲ°еә•иҗҪе…ҘжЎ¶еҶ…зҡ„е“ӘдёӘдҪҚзҪ®пјҲдёҖдёӘжЎ¶еҶ…жңҖеӨҡжңү8дёӘдҪҚзҪ®) гҖӮ
bucketеҶ…еӯҳж•°жҚ®з»“жһ„еҸҜи§ҶеҢ–еҰӮдёӢпјҡ
жіЁж„ҸеҲ° key е’Ң value жҳҜеҗ„иҮӘж”ҫеңЁдёҖиө·зҡ„пјҢ并дёҚжҳҜkey/value/key/value/...иҝҷж ·зҡ„еҪўејҸ гҖӮжәҗз ҒйҮҢиҜҙжҳҺиҝҷж ·зҡ„еҘҪеӨ„жҳҜеңЁжҹҗдәӣжғ…еҶөдёӢеҸҜд»ҘзңҒз•ҘжҺү paddingеӯ—ж®өпјҢиҠӮзңҒеҶ…еӯҳз©әй—ҙ гҖӮ
еҪ“ map зҡ„ key е’Ң value йғҪдёҚжҳҜжҢҮй’ҲпјҢ并且 size йғҪе°ҸдәҺ 128 еӯ—иҠӮзҡ„жғ…еҶөдёӢпјҢдјҡжҠҠ bmap ж Үи®°дёәдёҚеҗ«жҢҮй’ҲпјҢиҝҷж ·еҸҜд»ҘйҒҝе…Қ gc ж—¶жү«жҸҸж•ҙдёӘ hmap гҖӮдҪҶжҳҜ пјҢ жҲ‘们зңӢ bmap е…¶е®һжңүдёҖдёӘ overflow зҡ„еӯ—ж®өпјҢжҳҜжҢҮй’Ҳзұ»еһӢзҡ„пјҢз ҙеқҸдәҶ bmap дёҚеҗ«жҢҮй’Ҳзҡ„и®ҫжғі пјҢ иҝҷж—¶дјҡжҠҠ overflow 移еҠЁеҲ° extra еӯ—ж®өжқҘ гҖӮ
mapжҳҜдёӘжҢҮй’ҲпјҢеә•еұӮжҢҮеҗ‘hmapпјҢжүҖд»ҘжҳҜдёӘеј•з”Ёзұ»еһӢ
golang жңүдёүдёӘеёёз”Ёзҡ„й«ҳзә§зұ»еһӢ slice гҖҒmapгҖҒchannel,е®ғ们йғҪжҳҜ еј•з”Ёзұ»еһӢ пјҢ еҪ“еј•з”Ёзұ»еһӢдҪңдёәеҮҪж•°еҸӮж•°ж—¶пјҢеҸҜиғҪдјҡдҝ®ж”№еҺҹеҶ…е®№ж•°жҚ® гҖӮ
golang дёӯжІЎжңүеј•з”Ёдј йҖ’пјҢеҸӘжңүеҖје’ҢжҢҮй’Ҳдј йҖ’ гҖӮжүҖд»Ҙ map дҪңдёәеҮҪж•°е®һеҸӮдј йҖ’ж—¶жң¬иҙЁдёҠд№ҹжҳҜеҖјдј йҖ’пјҢеҸӘдёҚиҝҮеӣ дёә map еә•еұӮж•°жҚ®з»“жһ„жҳҜйҖҡиҝҮжҢҮй’ҲжҢҮеҗ‘е®һйҷ…зҡ„е…ғзҙ еӯҳеӮЁз©әй—ҙпјҢеңЁиў«и°ғеҮҪж•°дёӯдҝ®ж”№ map пјҢ еҜ№и°ғз”ЁиҖ…еҗҢж ·еҸҜи§ҒпјҢжүҖд»Ҙ map дҪңдёәеҮҪж•°е®һеҸӮдј йҖ’ж—¶иЎЁзҺ°еҮәдәҶеј•з”Ёдј йҖ’зҡ„ж•Ҳжһң гҖӮ
еӣ жӯӨпјҢдј йҖ’ map ж—¶пјҢеҰӮжһңжғідҝ®ж”№mapзҡ„еҶ…е®№иҖҢдёҚжҳҜmapжң¬иә«пјҢеҮҪж•°еҪўеҸӮж— йңҖдҪҝз”ЁжҢҮй’Ҳ
mapеә•еұӮж•°жҚ®з»“жһ„жҳҜйҖҡиҝҮжҢҮй’ҲжҢҮеҗ‘е®һйҷ…зҡ„е…ғзҙ еӯҳеӮЁз©әй—ҙпјҢиҝҷз§Қжғ…еҶөдёӢпјҢеҜ№е…¶дёӯдёҖдёӘmapзҡ„жӣҙж”№пјҢдјҡеҪұе“ҚеҲ°е…¶д»–map
map еңЁжІЎжңүиў«дҝ®ж”№зҡ„жғ…еҶөдёӢпјҢдҪҝз”Ё range еӨҡж¬ЎйҒҚеҺҶ map ж—¶иҫ“еҮәзҡ„ key е’Ң value зҡ„йЎәеәҸеҸҜиғҪдёҚеҗҢ гҖӮиҝҷжҳҜ Go иҜӯиЁҖзҡ„и®ҫи®ЎиҖ…们жңүж„Ҹдёәд№ӢпјҢеңЁжҜҸж¬Ў range ж—¶зҡ„йЎәеәҸиў«йҡҸжңәеҢ–пјҢж—ЁеңЁжҸҗзӨәејҖеҸ‘иҖ…们пјҢGo еә•еұӮе®һзҺ°е№¶дёҚдҝқиҜҒ map йҒҚеҺҶйЎәеәҸзЁіе®ҡпјҢиҜ·еӨ§е®¶дёҚиҰҒдҫқиө– range йҒҚеҺҶз»“жһңйЎәеәҸ гҖӮ
map жң¬иә«жҳҜж— еәҸзҡ„пјҢдё”йҒҚеҺҶж—¶йЎәеәҸиҝҳдјҡиў«йҡҸжңәеҢ–пјҢеҰӮжһңжғійЎәеәҸйҒҚеҺҶ mapпјҢйңҖиҰҒеҜ№ map key е…ҲжҺ’еәҸ пјҢ еҶҚжҢүз…§ key зҡ„йЎәеәҸйҒҚеҺҶ map гҖӮ
mapй»ҳи®ӨжҳҜ并еҸ‘дёҚе®үе…Ёзҡ„ пјҢ еҺҹеӣ еҰӮдёӢпјҡ
Go е®ҳж–№еңЁз»ҸиҝҮдәҶй•ҝж—¶й—ҙзҡ„и®Ёи®әеҗҺпјҢи®Өдёә Go map жӣҙеә”йҖӮй…Қе…ёеһӢдҪҝз”ЁеңәжҷҜпјҲдёҚйңҖиҰҒд»ҺеӨҡдёӘ goroutine дёӯиҝӣиЎҢе®үе…Ёи®ҝй—®пјү пјҢ иҖҢдёҚжҳҜдёәдәҶе°ҸйғЁеҲҶжғ…еҶөпјҲ并еҸ‘и®ҝй—®пјүпјҢеҜјиҮҙеӨ§йғЁеҲҶзЁӢеәҸд»ҳеҮәеҠ й”Ғд»Јд»·пјҲжҖ§иғҪпјүпјҢеҶіе®ҡдәҶдёҚж”ҜжҢҒ гҖӮ
еңәжҷҜ:2дёӘеҚҸзЁӢеҗҢж—¶иҜ»е’ҢеҶҷпјҢд»ҘдёӢзЁӢеәҸдјҡеҮәзҺ°иҮҙе‘Ҫй”ҷиҜҜпјҡfatal error: concurrent map writes
еҰӮжһңжғіе®һзҺ°mapзәҝзЁӢе®үе…ЁпјҢжңүдёӨз§Қж–№ејҸпјҡ
ж–№ејҸдёҖпјҡдҪҝз”ЁиҜ»еҶҷй”Ғmapsync.RWMutex
ж–№ејҸдәҢпјҡдҪҝз”ЁgolangжҸҗдҫӣзҡ„sync.Map
sync.mapжҳҜз”ЁиҜ»еҶҷеҲҶзҰ»е®һзҺ°зҡ„пјҢе…¶жҖқжғіжҳҜз©әй—ҙжҚўж—¶й—ҙ гҖӮе’Ңmap RWLockзҡ„е®һзҺ°ж–№ејҸзӣёжҜ”пјҢе®ғеҒҡдәҶдёҖдәӣдјҳеҢ–пјҡеҸҜд»Ҙж— й”Ғи®ҝй—®read map пјҢ иҖҢдё”дјҡдјҳе…Ҳж“ҚдҪңread map пјҢ еҖҳиӢҘеҸӘж“ҚдҪңread mapе°ұеҸҜд»Ҙж»Ўи¶іиҰҒжұӮ(еўһеҲ ж”№жҹҘйҒҚеҺҶ)пјҢйӮЈе°ұдёҚз”ЁеҺ»ж“ҚдҪңwrite map(е®ғзҡ„иҜ»еҶҷйғҪиҰҒеҠ й”Ғ)пјҢжүҖд»ҘеңЁжҹҗдәӣзү№е®ҡеңәжҷҜдёӯе®ғеҸ‘з”ҹй”Ғз«һдәүзҡ„йў‘зҺҮдјҡиҝңиҝңе°ҸдәҺmap RWLockзҡ„е®һзҺ°ж–№ејҸ гҖӮ
golangдёӯmapжҳҜдёҖдёӘkvеҜ№йӣҶеҗҲ гҖӮеә•еұӮдҪҝз”Ёhash tableпјҢз”Ёй“ҫиЎЁжқҘи§ЈеҶіеҶІзӘҒпјҢеҮәзҺ°еҶІзӘҒж—¶пјҢдёҚжҳҜжҜҸдёҖдёӘkeyйғҪз”іиҜ·дёҖдёӘз»“жһ„йҖҡиҝҮй“ҫиЎЁдёІиө·жқҘпјҢиҖҢжҳҜд»ҘbmapдёәжңҖе°ҸзІ’еәҰжҢӮиҪҪпјҢдёҖдёӘbmapеҸҜд»Ҙж”ҫ8дёӘkv гҖӮеңЁе“ҲеёҢеҮҪж•°зҡ„йҖүжӢ©дёҠпјҢдјҡеңЁзЁӢеәҸеҗҜеҠЁж—¶ пјҢ жЈҖжөӢ cpu жҳҜеҗҰж”ҜжҢҒ aesпјҢеҰӮжһңж”ҜжҢҒпјҢеҲҷдҪҝз”Ё aes hash пјҢ еҗҰеҲҷдҪҝз”Ё memhash гҖӮ
mapжңү3й’ҹеҲқе§ӢеҢ–ж–№ејҸпјҢдёҖиҲ¬йҖҡиҝҮmakeж–№ејҸеҲӣе»ә
mapзҡ„еҲӣе»әйҖҡиҝҮз”ҹжҲҗжұҮзј–з ҒеҸҜд»ҘзҹҘйҒ“пјҢmakeеҲӣе»әmapж—¶и°ғз”Ёзҡ„еә•еұӮеҮҪж•°жҳҜ runtime.makemapгҖӮеҰӮжһңдҪ зҡ„mapеҲқе§Ӣе®№йҮҸе°ҸдәҺзӯүдәҺ8дјҡеҸ‘зҺ°иө°зҡ„жҳҜ runtime.fastrand жҳҜеӣ дёәе®№йҮҸе°ҸдәҺ8ж—¶дёҚйңҖиҰҒз”ҹжҲҗеӨҡдёӘжЎ¶пјҢдёҖдёӘжЎ¶зҡ„е®№йҮҸе°ұеҸҜд»Ҙж»Ўи¶і
makemapеҮҪж•°дјҡйҖҡиҝҮfastrandеҲӣе»әдёҖдёӘйҡҸжңәзҡ„е“ҲеёҢз§ҚеӯҗпјҢ然еҗҺж №жҚ®дј е…Ҙзҡ„hintи®Ўз®—еҮәйңҖиҰҒзҡ„жңҖе°ҸйңҖиҰҒзҡ„жЎ¶зҡ„ж•°йҮҸпјҢжңҖеҗҺеҶҚдҪҝз”ЁmakeBucketArray еҲӣе»әз”ЁдәҺдҝқеӯҳжЎ¶зҡ„ж•°з»„пјҢиҝҷдёӘж–№жі•е…¶е®һе°ұжҳҜж №жҚ®дј е…Ҙзҡ„Bи®Ўз®—еҮәзҡ„йңҖиҰҒеҲӣе»әзҡ„жЎ¶ж•°йҮҸеңЁеҶ…еӯҳдёӯеҲҶй…ҚдёҖзүҮиҝһз»ӯзҡ„з©әй—ҙз”ЁдәҺеӯҳеӮЁж•°жҚ®пјҢеңЁеҲӣе»әжЎ¶зҡ„иҝҮзЁӢдёӯиҝҳдјҡйўқеӨ–еҲӣе»әдёҖдәӣз”ЁдәҺдҝқеӯҳжәўеҮәж•°жҚ®зҡ„жЎ¶пјҢж•°йҮҸжҳҜ2^(B-4)дёӘ гҖӮеҲқе§ӢеҢ–е®ҢжҲҗиҝ”еӣһhmapжҢҮй’Ҳ гҖӮ
жүҫеҲ°дёҖдёӘ BпјҢдҪҝеҫ— map зҡ„иЈ…иҪҪеӣ еӯҗеңЁжӯЈеёёиҢғеӣҙеҶ…
Go иҜӯиЁҖдёӯиҜ»еҸ– map жңүдёӨз§ҚиҜӯжі•пјҡеёҰ comma е’Ң дёҚеёҰ comma гҖӮеҪ“иҰҒжҹҘиҜўзҡ„ key дёҚеңЁ map йҮҢпјҢеёҰ comma зҡ„з”Ёжі•дјҡиҝ”еӣһдёҖдёӘ bool еһӢеҸҳйҮҸжҸҗзӨә key жҳҜеҗҰеңЁ map дёӯпјӣиҖҢдёҚеёҰ comma зҡ„иҜӯеҸҘеҲҷдјҡиҝ”еӣһдёҖдёӘ value зұ»еһӢзҡ„йӣ¶еҖј гҖӮеҰӮжһң value жҳҜ int еһӢе°ұдјҡиҝ”еӣһ 0пјҢеҰӮжһң value жҳҜ string зұ»еһӢпјҢе°ұдјҡиҝ”еӣһз©әеӯ—з¬ҰдёІ гҖӮ
mapзҡ„жҹҘжүҫйҖҡиҝҮз”ҹжҲҗжұҮзј–з ҒеҸҜд»ҘзҹҘйҒ“ пјҢ ж №жҚ® key зҡ„дёҚеҗҢзұ»еһӢпјҢзј–иҜ‘еҷЁдјҡе°ҶжҹҘжүҫеҮҪж•°з”Ёжӣҙе…·дҪ“зҡ„еҮҪж•°жӣҝжҚўпјҢд»ҘдјҳеҢ–ж•ҲзҺҮпјҡ
еҮҪж•°йҰ–е…ҲдјҡжЈҖжҹҘ map зҡ„ж Үеҝ—дҪҚ flags гҖӮеҰӮжһң flags зҡ„еҶҷж Үеҝ—дҪҚжӯӨж—¶иў«зҪ® 1 дәҶпјҢиҜҙжҳҺжңүе…¶д»–еҚҸзЁӢеңЁжү§иЎҢвҖңеҶҷвҖқж“ҚдҪң пјҢ иҝӣиҖҢеҜјиҮҙзЁӢеәҸ panic гҖӮиҝҷд№ҹиҜҙжҳҺдәҶ map еҜ№еҚҸзЁӢжҳҜдёҚе®үе…Ёзҡ„ гҖӮ
keyз»ҸиҝҮе“ҲеёҢеҮҪж•°и®Ўз®—еҗҺпјҢеҫ—еҲ°зҡ„е“ҲеёҢеҖјеҰӮдёӢпјҲдё»жөҒ64дҪҚжңәдёӢе…ұ 64 дёӘ bit дҪҚпјүпјҡ
m: жЎ¶зҡ„дёӘж•°
д»Һbuckets йҖҡиҝҮ hashm еҫ—еҲ°еҜ№еә”зҡ„bucket пјҢ еҰӮжһңbucketжӯЈеңЁжү©е®№пјҢ并且没жңүжү©е®№е®ҢжҲҗпјҢеҲҷд»Һoldbucketsеҫ—еҲ°еҜ№еә”зҡ„bucket
и®Ўз®—hashжүҖеңЁжЎ¶зј–еҸ·пјҡ
з”ЁдёҠдёҖжӯҘе“ҲеёҢеҖјжңҖеҗҺзҡ„ 5 дёӘ bit дҪҚпјҢд№ҹе°ұжҳҜ01010 пјҢеҖјдёә 10пјҢд№ҹе°ұжҳҜ 10 еҸ·жЎ¶пјҲиҢғеӣҙжҳҜ0~31еҸ·жЎ¶пјү
и®Ўз®—hashжүҖеңЁзҡ„ж§ҪдҪҚ:
з”ЁдёҠдёҖжӯҘе“ҲеёҢеҖје“ҲеёҢеҖјзҡ„й«ҳ8дёӘbit дҪҚпјҢд№ҹе°ұжҳҜ 10010111пјҢиҪ¬еҢ–дёәеҚҒиҝӣеҲ¶пјҢд№ҹе°ұжҳҜ151 пјҢ еңЁ 10 еҸ· bucket дёӯеҜ»жүҫ** tophash еҖјпјҲHOB hashпјүдёә 151* зҡ„ ж§ҪдҪҚ**пјҢеҚідёәkeyжүҖеңЁдҪҚзҪ®пјҢжүҫеҲ°дәҶ 2 еҸ·ж§ҪдҪҚпјҢиҝҷж ·ж•ҙдёӘжҹҘжүҫиҝҮзЁӢе°ұз»“жқҹдәҶ гҖӮ
еҰӮжһңеңЁ bucket дёӯжІЎжүҫеҲ°пјҢ并且 overflow дёҚдёәз©әпјҢиҝҳиҰҒ继з»ӯеҺ» overflow bucket дёӯеҜ»жүҫ пјҢ зӣҙеҲ°жүҫеҲ°жҲ–жҳҜжүҖжңүзҡ„ key ж§ҪдҪҚйғҪжүҫйҒҚдәҶпјҢеҢ…жӢ¬жүҖжңүзҡ„ overflow bucket гҖӮ
йҖҡиҝҮдёҠйқўжүҫеҲ°дәҶеҜ№еә”зҡ„ж§ҪдҪҚпјҢиҝҷйҮҢжҲ‘们еҶҚиҜҰз»ҶеҲҶжһҗдёӢkey/valueеҖјжҳҜеҰӮдҪ•иҺ·еҸ–зҡ„пјҡ
bucket йҮҢ key зҡ„иө·е§Ӣең°еқҖе°ұжҳҜ unsafe.Pointer(b) dataOffset гҖӮ第 i дёӘ key зҡ„ең°еқҖе°ұиҰҒеңЁжӯӨеҹәзЎҖдёҠи·ЁиҝҮ i дёӘ key зҡ„еӨ§?гҖӮж¬ўоүЎйўҗжҖҜз§ҚоҖ”?пјҢvalue зҡ„ең°еқҖжҳҜеңЁжүҖжңү key д№ӢеҗҺпјҢеӣ жӯӨ第 i дёӘ value зҡ„ең°еқҖиҝҳйңҖиҰҒеҠ дёҠжүҖжңү key зҡ„еҒҸ移 гҖӮ
йҖҡиҝҮжұҮзј–иҜӯиЁҖеҸҜд»ҘзңӢеҲ° пјҢ еҗ‘ map дёӯжҸ’е…ҘжҲ–иҖ…дҝ®ж”№ keyпјҢжңҖз»Ҳи°ғз”Ёзҡ„жҳҜmapassignеҮҪж•° гҖӮ
е®һйҷ…дёҠжҸ’е…ҘжҲ–дҝ®ж”№ key зҡ„иҜӯжі•жҳҜдёҖж ·зҡ„пјҢеҸӘдёҚиҝҮеүҚиҖ…ж“ҚдҪңзҡ„ key еңЁ map дёӯдёҚеӯҳеңЁ пјҢ иҖҢеҗҺиҖ…ж“ҚдҪңзҡ„ key еӯҳеңЁ map дёӯ гҖӮ
mapassign жңүдёҖдёӘзі»еҲ—зҡ„еҮҪж•°пјҢж №жҚ® key зұ»еһӢзҡ„дёҚеҗҢ пјҢ зј–иҜ‘еҷЁдјҡе°Ҷе…¶дјҳеҢ–дёәзӣёеә”зҡ„вҖңеҝ«йҖҹеҮҪж•°вҖқ гҖӮ
жҲ‘们еҸӘз”Ёз ”з©¶жңҖдёҖиҲ¬зҡ„иөӢеҖјеҮҪж•°mapassignгҖӮ
mapзҡ„иөӢеҖјдјҡйҷ„еёҰзқҖmapзҡ„жү©е®№е’ҢиҝҒ移пјҢmapзҡ„жү©е®№еҸӘжҳҜе°Ҷеә•еұӮж•°з»„жү©еӨ§дәҶдёҖеҖҚпјҢ并没жңүиҝӣиЎҢж•°жҚ®зҡ„иҪ¬з§» пјҢ ж•°жҚ®зҡ„иҪ¬з§»жҳҜеңЁжү©е®№еҗҺйҖҗжӯҘиҝӣиЎҢзҡ„пјҢеңЁиҝҒ移зҡ„иҝҮзЁӢдёӯжҜҸиҝӣиЎҢдёҖж¬ЎиөӢеҖјпјҲaccessжҲ–иҖ…deleteпјүдјҡиҮіе°‘еҒҡдёҖж¬ЎиҝҒ移е·ҘдҪң гҖӮ
1.еҲӨж–ӯmapжҳҜеҗҰдёәnil
жҜҸдёҖж¬ЎиҝӣиЎҢиөӢеҖј/еҲ йҷӨж“ҚдҪңж—¶пјҢеҸӘиҰҒoldbuckets != nil еҲҷи®ӨдёәжӯЈеңЁжү©е®№пјҢдјҡеҒҡдёҖж¬ЎиҝҒ移е·ҘдҪңпјҢдёӢйқўдјҡиҜҰз»ҶиҜҙдёӢиҝҒ移иҝҮзЁӢ
ж №жҚ®дёҠйқўжҹҘжүҫиҝҮзЁӢпјҢжҹҘжүҫkeyжүҖеңЁдҪҚзҪ® пјҢ еҰӮжһңжүҫеҲ°еҲҷжӣҙж–°пјҢжІЎжүҫеҲ°еҲҷжүҫз©әдҪҚжҸ’е…ҘеҚіеҸҜ
з»ҸиҝҮеүҚйқўиҝӯд»ЈеҜ»жүҫеҠЁдҪң пјҢ иӢҘжІЎжңүжүҫеҲ°еҸҜжҸ’е…Ҙзҡ„дҪҚзҪ®пјҢж„Ҹе‘ізқҖйңҖиҰҒжү©е®№иҝӣиЎҢжҸ’е…ҘпјҢдёӢйқўдјҡиҜҰз»ҶиҜҙдёӢжү©е®№иҝҮзЁӢ
йҖҡиҝҮжұҮзј–иҜӯиЁҖеҸҜд»ҘзңӢеҲ°пјҢеҗ‘ map дёӯеҲ йҷӨ keyпјҢжңҖз»Ҳи°ғз”Ёзҡ„жҳҜmapdeleteеҮҪж•°
еҲ йҷӨзҡ„йҖ»иҫ‘зӣёеҜ№жҜ”иҫғз®ҖеҚ• пјҢ еӨ§еӨҡеҮҪж•°еңЁиөӢеҖјж“ҚдҪңдёӯе·Із»Ҹз”ЁеҲ°иҝҮпјҢж ёеҝғиҝҳжҳҜжүҫеҲ° key зҡ„е…·дҪ“дҪҚзҪ® гҖӮеҜ»жүҫиҝҮзЁӢйғҪжҳҜзұ»дјјзҡ„пјҢеңЁ bucket дёӯжҢЁдёӘ cell еҜ»жүҫ гҖӮжүҫеҲ°еҜ№еә”дҪҚзҪ®еҗҺпјҢеҜ№ key жҲ–иҖ… value иҝӣиЎҢвҖңжё…йӣ¶вҖқж“ҚдҪңпјҢе°Ҷ count еҖјеҮҸ 1пјҢе°ҶеҜ№еә”дҪҚзҪ®зҡ„ tophash еҖјзҪ®жҲҗEmpty
еҶҚжқҘиҜҙи§ҰеҸ‘ map жү©е®№зҡ„ж—¶жңәпјҡеңЁеҗ‘ map жҸ’е…Ҙж–° key зҡ„ж—¶еҖҷпјҢдјҡиҝӣиЎҢжқЎд»¶жЈҖжөӢпјҢз¬ҰеҗҲдёӢйқўиҝҷ 2 дёӘжқЎд»¶пјҢе°ұдјҡи§ҰеҸ‘жү©е®№пјҡ
1гҖҒиЈ…иҪҪеӣ еӯҗи¶…иҝҮйҳҲеҖј
жәҗз ҒйҮҢе®ҡд№үзҡ„йҳҲеҖјжҳҜ 6.5 (loadFactorNum/loadFactorDen)пјҢжҳҜз»ҸиҝҮжөӢиҜ•еҗҺеҸ–еҮәзҡ„дёҖдёӘжҜ”иҫғеҗҲзҗҶзҡ„еӣ еӯҗ
жҲ‘们зҹҘйҒ“ пјҢ жҜҸдёӘ bucket жңү 8 дёӘз©әдҪҚпјҢеңЁжІЎжңүжәўеҮәпјҢдё”жүҖжңүзҡ„жЎ¶йғҪиЈ…ж»ЎдәҶзҡ„жғ…еҶөдёӢпјҢиЈ…иҪҪеӣ еӯҗз®—еҮәжқҘзҡ„з»“жһңжҳҜ 8 гҖӮеӣ жӯӨеҪ“иЈ…иҪҪеӣ еӯҗи¶…иҝҮ 6.5 ж—¶пјҢиЎЁжҳҺеҫҲеӨҡ bucket йғҪеҝ«иҰҒиЈ…ж»ЎдәҶ пјҢ жҹҘжүҫж•ҲзҺҮе’ҢжҸ’е…Ҙж•ҲзҺҮйғҪеҸҳдҪҺдәҶ гҖӮеңЁиҝҷдёӘж—¶еҖҷиҝӣиЎҢжү©е®№жҳҜжңүеҝ…иҰҒзҡ„ гҖӮ
еҜ№дәҺжқЎд»¶ 1пјҢе…ғзҙ еӨӘеӨҡпјҢиҖҢ bucket ж•°йҮҸеӨӘе°‘пјҢеҫҲз®ҖеҚ•пјҡе°Ҷ B еҠ 1пјҢbucket жңҖеӨ§ж•°йҮҸ( 2^B )зӣҙжҺҘеҸҳжҲҗеҺҹжқҘ bucket ж•°йҮҸзҡ„ 2 еҖҚ гҖӮдәҺжҳҜпјҢе°ұжңүж–°иҖҒ bucket дәҶ гҖӮжіЁж„Ҹ пјҢ иҝҷж—¶еҖҷе…ғзҙ йғҪеңЁиҖҒ bucket йҮҢпјҢиҝҳжІЎиҝҒ移еҲ°ж–°зҡ„ bucket жқҘ гҖӮж–° bucket еҸӘжҳҜжңҖеӨ§ж•°йҮҸеҸҳдёәеҺҹжқҘжңҖеӨ§ж•°йҮҸзҡ„ 2 еҖҚ( 2^B * 2 )гҖӮ
2гҖҒoverflow зҡ„ bucket ж•°йҮҸиҝҮеӨҡ
еңЁиЈ…иҪҪеӣ еӯҗжҜ”иҫғе°Ҹзҡ„жғ…еҶөдёӢ пјҢ иҝҷж—¶еҖҷ map зҡ„жҹҘжүҫе’ҢжҸ’е…Ҙж•ҲзҺҮд№ҹеҫҲдҪҺпјҢиҖҢ第 1 зӮ№иҜҶеҲ«дёҚеҮәжқҘиҝҷз§Қжғ…еҶө гҖӮиЎЁйқўзҺ°иұЎе°ұжҳҜи®Ўз®—иЈ…иҪҪеӣ еӯҗзҡ„еҲҶеӯҗжҜ”иҫғе°ҸпјҢеҚі map йҮҢе…ғзҙ жҖ»ж•°е°‘ пјҢ дҪҶжҳҜ bucket ж•°йҮҸеӨҡпјҲзңҹе®һеҲҶй…Қзҡ„ bucket ж•°йҮҸеӨҡпјҢеҢ…жӢ¬еӨ§йҮҸзҡ„ overflow bucketпјү
дёҚйҡҫжғіеғҸйҖ жҲҗиҝҷз§Қжғ…еҶөзҡ„еҺҹеӣ пјҡдёҚеҒңең°жҸ’е…ҘгҖҒеҲ йҷӨе…ғзҙ гҖӮе…ҲжҸ’е…ҘеҫҲеӨҡе…ғзҙ пјҢ еҜјиҮҙеҲӣе»әдәҶеҫҲеӨҡ bucketпјҢдҪҶжҳҜиЈ…иҪҪеӣ еӯҗиҫҫдёҚеҲ°з¬¬ 1 зӮ№зҡ„дёҙз•ҢеҖјпјҢжңӘи§ҰеҸ‘жү©е®№жқҘзј“и§Јиҝҷз§Қжғ…еҶө гҖӮд№ӢеҗҺпјҢеҲ йҷӨе…ғзҙ йҷҚдҪҺе…ғзҙ жҖ»ж•°йҮҸпјҢеҶҚжҸ’е…ҘеҫҲеӨҡе…ғзҙ пјҢеҜјиҮҙеҲӣе»әеҫҲеӨҡзҡ„ overflow bucketпјҢдҪҶе°ұжҳҜдёҚдјҡи§ҰеҸ‘第 1 зӮ№зҡ„规е®ҡпјҢдҪ иғҪжӢҝжҲ‘жҖҺд№ҲеҠһпјҹoverflow bucket ж•°йҮҸеӨӘеӨҡпјҢеҜјиҮҙ key дјҡеҫҲеҲҶж•ЈпјҢжҹҘжүҫжҸ’е…Ҙж•ҲзҺҮдҪҺеҫ—еҗ“дәә пјҢ еӣ жӯӨеҮәеҸ°з¬¬ 2 зӮ№и§„е®ҡ гҖӮиҝҷе°ұеғҸжҳҜдёҖеә§з©әеҹҺ пјҢ жҲҝеӯҗеҫҲеӨҡпјҢдҪҶжҳҜдҪҸжҲ·еҫҲе°‘пјҢйғҪеҲҶж•ЈдәҶ пјҢ жүҫиө·дәәжқҘеҫҲеӣ°йҡҫ
еҜ№дәҺжқЎд»¶ 2пјҢе…¶е®һе…ғзҙ жІЎйӮЈд№ҲеӨҡпјҢдҪҶжҳҜ overflow bucket ж•°зү№еҲ«еӨҡпјҢиҜҙжҳҺеҫҲеӨҡ bucket йғҪжІЎиЈ…ж»Ў гҖӮи§ЈеҶіеҠһжі•е°ұжҳҜејҖиҫҹдёҖдёӘж–° bucket з©әй—ҙпјҢе°ҶиҖҒ bucket дёӯзҡ„е…ғзҙ 移еҠЁеҲ°ж–° bucketпјҢдҪҝеҫ—еҗҢдёҖдёӘ bucket дёӯзҡ„ key жҺ’еҲ—ең°жӣҙзҙ§еҜҶ гҖӮиҝҷж ·пјҢеҺҹжқҘ пјҢ еңЁ overflow bucket дёӯзҡ„ key еҸҜд»Ҙ移еҠЁеҲ° bucket дёӯжқҘ гҖӮз»“жһңжҳҜиҠӮзңҒз©әй—ҙпјҢжҸҗй«ҳ bucket еҲ©з”ЁзҺҮпјҢmap зҡ„жҹҘжүҫе’ҢжҸ’е…Ҙж•ҲзҺҮиҮӘ然е°ұдјҡжҸҗеҚҮ гҖӮ
з”ұдәҺ map жү©е®№йңҖиҰҒе°ҶеҺҹжңүзҡ„ key/value йҮҚж–°жҗ¬иҝҒеҲ°ж–°зҡ„еҶ…еӯҳең°еқҖпјҢеҰӮжһңжңүеӨ§йҮҸзҡ„ key/value йңҖиҰҒжҗ¬иҝҒпјҢдјҡйқһеёёеҪұе“ҚжҖ§иғҪ гҖӮеӣ жӯӨ Go map зҡ„жү©е®№йҮҮеҸ–дәҶдёҖз§Қз§°дёәвҖңжёҗиҝӣејҸвҖқзҡ„ж–№ејҸпјҢеҺҹжңүзҡ„ key 并дёҚдјҡдёҖж¬ЎжҖ§жҗ¬иҝҒе®ҢжҜ• пјҢ жҜҸж¬ЎжңҖеӨҡеҸӘдјҡжҗ¬иҝҒ 2 дёӘ bucket гҖӮ
дёҠйқўиҜҙзҡ„hashGrow()еҮҪж•°е®һйҷ…дёҠ并没жңүзңҹжӯЈең°вҖңжҗ¬иҝҒвҖқпјҢе®ғеҸӘжҳҜеҲҶй…ҚеҘҪдәҶж–°зҡ„ bucketsпјҢ并е°ҶиҖҒзҡ„ buckets жҢӮеҲ°дәҶ oldbuckets еӯ—ж®өдёҠ гҖӮзңҹжӯЈжҗ¬иҝҒ buckets зҡ„еҠЁдҪңеңЁgrowWork()еҮҪж•°дёӯпјҢиҖҢи°ғз”ЁgrowWork()еҮҪж•°зҡ„еҠЁдҪңжҳҜеңЁ mapassign е’Ң mapdelete еҮҪж•°дёӯ гҖӮд№ҹе°ұжҳҜжҸ’е…ҘжҲ–дҝ®ж”№гҖҒеҲ йҷӨ key зҡ„ж—¶еҖҷпјҢйғҪдјҡе°қиҜ•иҝӣиЎҢжҗ¬иҝҒ buckets зҡ„е·ҘдҪң гҖӮе…ҲжЈҖжҹҘ oldbuckets жҳҜеҗҰжҗ¬иҝҒе®ҢжҜ•пјҢе…·дҪ“жқҘиҜҙе°ұжҳҜжЈҖжҹҘ oldbuckets жҳҜеҗҰдёә nil гҖӮ
еҰӮжһңжңӘиҝҒ移е®ҢжҜ•пјҢиөӢеҖј/еҲ йҷӨзҡ„ж—¶еҖҷпјҢжү©е®№е®ҢжҜ•еҗҺпјҲйў„еҲҶй…ҚеҶ…еӯҳпјүпјҢдёҚдјҡ马дёҠе°ұиҝӣиЎҢиҝҒ移 гҖӮиҖҢжҳҜйҮҮеҸ– еўһйҮҸжү©е®№ зҡ„ж–№ејҸпјҢеҪ“жңүи®ҝй—®еҲ°е…·дҪ“ bukcet ж—¶пјҢжүҚдјҡйҖҗжёҗзҡ„иҝӣиЎҢиҝҒ移пјҲе°Ҷ oldbucket иҝҒ移еҲ° bucketпјү
nevacuate ж ҮиҜҶзҡ„жҳҜеҪ“еүҚзҡ„иҝӣеәҰпјҢеҰӮжһңйғҪжҗ¬иҝҒе®Ң пјҢ еә”иҜҘе’Ң2^Bзҡ„й•ҝеәҰжҳҜдёҖж ·зҡ„
еңЁevacuate ж–№жі•е®һзҺ°жҳҜжҠҠиҝҷдёӘдҪҚзҪ®еҜ№еә”зҡ„bucketпјҢд»ҘеҸҠе…¶еҶІзӘҒй“ҫдёҠзҡ„ж•°жҚ®йғҪиҪ¬з§»еҲ°ж–°зҡ„bucketsдёҠ гҖӮ
иҪ¬з§»зҡ„еҲӨж–ӯзӣҙжҺҘйҖҡиҝҮtophash е°ұеҸҜд»Ҙ пјҢ еҲӨж–ӯtophashдёӯ第дёҖдёӘhashеҖјеҚіеҸҜ
йҒҚеҺҶзҡ„иҝҮзЁӢпјҢе°ұжҳҜжҢүйЎәеәҸйҒҚеҺҶ bucketпјҢеҗҢж—¶жҢүйЎәеәҸйҒҚеҺҶ bucket дёӯзҡ„ key гҖӮ
mapйҒҚеҺҶжҳҜж— еәҸзҡ„пјҢеҰӮжһңжғіе®һзҺ°жңүеәҸйҒҚеҺҶпјҢеҸҜд»Ҙе…ҲеҜ№keyиҝӣиЎҢжҺ’еәҸ
дёәд»Җд№ҲйҒҚеҺҶ map жҳҜж— еәҸзҡ„пјҹ
еҰӮжһңеҸ‘з”ҹиҝҮиҝҒ移пјҢkey зҡ„дҪҚзҪ®еҸ‘з”ҹдәҶйҮҚеӨ§зҡ„еҸҳеҢ– пјҢ жңүдәӣ key йЈһдёҠй«ҳжһқпјҢжңүдәӣ key еҲҷеҺҹең°дёҚеҠЁ гҖӮиҝҷж ·пјҢйҒҚеҺҶ map зҡ„з»“жһңе°ұдёҚеҸҜиғҪжҢүеҺҹжқҘзҡ„йЎәеәҸдәҶ гҖӮ
еҰӮжһңе°ұдёҖдёӘеҶҷжӯ»зҡ„ map пјҢ дёҚдјҡеҗ‘ map иҝӣиЎҢжҸ’е…ҘеҲ йҷӨзҡ„ж“ҚдҪңпјҢжҢүзҗҶиҜҙжҜҸж¬ЎйҒҚеҺҶиҝҷж ·зҡ„ map йғҪдјҡиҝ”еӣһдёҖдёӘеӣәе®ҡйЎәеәҸзҡ„ key/value еәҸеҲ—еҗ§ гҖӮдҪҶжҳҜ Go жқңз»қдәҶиҝҷз§ҚеҒҡжі• пјҢ еӣ дёәиҝҷж ·дјҡз»ҷж–°жүӢзЁӢеәҸе‘ҳеёҰжқҘиҜҜи§ЈпјҢд»ҘдёәиҝҷжҳҜдёҖе®ҡдјҡеҸ‘з”ҹзҡ„дәӢжғ…пјҢеңЁжҹҗдәӣжғ…еҶөдёӢпјҢеҸҜиғҪдјҡй…ҝжҲҗеӨ§й”ҷ гҖӮ
Go еҒҡеҫ—жӣҙз»қпјҢеҪ“жҲ‘们еңЁйҒҚеҺҶ map ж—¶пјҢ并дёҚжҳҜеӣәе®ҡең°д»Һ 0 еҸ· bucket ејҖе§ӢйҒҚеҺҶпјҢжҜҸж¬ЎйғҪжҳҜд»ҺдёҖдёӘ**йҡҸжңәеҖјеәҸеҸ·зҡ„ bucketејҖе§ӢйҒҚеҺҶпјҢ并且жҳҜд»ҺиҝҷдёӘ bucket зҡ„дёҖдёӘ йҡҸжңәеәҸеҸ·зҡ„ cell **ејҖе§ӢйҒҚеҺҶ гҖӮиҝҷж ·пјҢеҚідҪҝдҪ жҳҜдёҖдёӘеҶҷжӯ»зҡ„ mapпјҢд»…д»…еҸӘжҳҜйҒҚеҺҶе®ғ пјҢ д№ҹдёҚеӨӘеҸҜиғҪдјҡиҝ”еӣһдёҖдёӘеӣәе®ҡеәҸеҲ—зҡ„ key/value еҜ№дәҶ гҖӮ
гҖҗgoиҜӯиЁҖsync.map goиҜӯиЁҖйҖӮеҗҲеҒҡд»Җд№ҲгҖ‘е…ідәҺgoиҜӯиЁҖsync.mapе’ҢgoиҜӯиЁҖйҖӮеҗҲеҒҡд»Җд№Ҳзҡ„д»Ӣз»ҚеҲ°жӯӨе°ұз»“жқҹдәҶпјҢдёҚзҹҘйҒ“дҪ д»ҺдёӯжүҫеҲ°дҪ йңҖиҰҒзҡ„дҝЎжҒҜдәҶеҗ— пјҹеҰӮжһңдҪ иҝҳжғідәҶи§ЈжӣҙеӨҡиҝҷж–№йқўзҡ„дҝЎжҒҜпјҢи®°еҫ—收и—Ҹе…іжіЁжң¬з«ҷ гҖӮ
жҺЁиҚҗйҳ…иҜ»






- flutterй•ҝз¬ӣе“ҒзүҢпјҢflutistй•ҝз¬ӣ
- жңҖеҘҪзҺ©е„ҝзҡ„е°„еҮ»жүӢжңәжёёжҲҸпјҢеҘҪзҺ©зҡ„е°„еҮ»жүӢжңәжёёжҲҸжҺЁиҚҗ
- жҠ“еҢ…и®ҫзҪ®д»ЈзҗҶжңҚеҠЎеҷЁзҡ„еҺҹеӣ пјҢжҠ“еҢ…authorization
- phpиҝ”еӣһж•°жҚ®еј№дёҚеҮә phpиҝ”еӣһж•°жҚ®еј№дёҚеҮәжқҘжҖҺд№ҲеҠһ
- еӣҫзүҮж— зјқж»ҡеҠЁjsзү№ж•Ҳд»Јз ҒпјҢеӣҫзүҮж»ҡеҠЁж•Ҳжһңд»Јз Ғ
- зҺ°д»ЈеӨ§ж•°жҚ®жҠҖжңҜиҜһз”ҹзҡ„ж Үеҝ—PythonпјҢеӨ§ж•°жҚ®ж—¶д»Јзҡ„ж–°жҠҖжңҜ
- йңҮдёңжЈӢзүҢзҡ„жүҖжңүжёёжҲҸпјҢйңҮдёңжЈӢзүҢе…‘жҚўз ҒеңЁе“ӘйўҶ
- javaд»Јз Ғи®ҝй—®html javaд»Јз Ғи®ҝй—®еҚҺдёәдә‘redis
- ж ·ејҸеј•з”ЁgisпјҢж ·ејҸеј•з”Ёеҹҹ